如何看待NeurIPS2023审稿结果?

- 189 个点赞 👍
查看全文>>
匿名用户 - 16 个点赞 👍
各位网友大家好,我是老胡,今天我们就来聊聊NeurIPS2023的审稿结果。看了我的三篇论文的审稿意见,我有些话想跟大家说说。
首先,谈到第一篇论文,这个分数分布真是“五花八门”。从3到6,似乎“山重水复疑无路,柳暗花明又一村”。对于其中给出3分的审稿人,我尊重你的观点,但是我仍然坚信,我的论文有其独特之处,有一定的学术价值。对于给6分的审稿人,我在这里感谢你们的认可,我会努力做到更好。而对于给出4分的评审,我想说,我会仔细阅读你的反馈,审视我的论文,并在rebuttal阶段尽力做出有力的反驳。
关于第二篇论文,这就好像“开弓没有回头箭”,有人认为它是顶级的工作,有人认为它尚需努力。我看到7分,我的心里充满了喜悦和欣慰。我看到3分,我觉得这是对我工作的挑战,也是我接下来需要面对的难题。毕竟,“人生能有几回搏”,我会在接下来的rebuttal阶段,全力以赴,展现我论文的价值。
至于第三篇论文,得到的分数平均偏低,这无疑是个重击。但我一直相信,一个真正的学者,不应因为一次的挫败而停下步伐。科研之路就是这样,你永远不知道下一次实验会得到什么样的结果。“人无远虑,必有近忧”,我不会因为这次的结果就放弃,反而会把它当作一个鞭策,努力做得更好。
我知道,在12000多篇有效投稿中,每一篇都是作者们倾注心血的作品,也同样面临着严格的审稿。这也是一个“人才出众”的现象,这是一个艰苦的竞争。我要告诉大家,科研不是一项轻松的工作,它需要才智、耐心和毅力。但只要你有决心,你就有可能在这场竞争中取得成功。
总的来说,我对这次的审稿结果充满了尊重和理解。无论结果如何,这都是一个学习和成长的过程。我会认真阅读每一位审稿人的反馈,从中学习,从中反思,从中提升。接下来的rebuttal阶段,老胡会“挺直腰板”,为自己的论文“亮剑”,努力争取最后的胜利。在这里,我也祝所有投稿NeurIPS的同行们,旗开得胜!
有些人可能会说,老胡,你这是“自找麻烦”,你这是“往火坑里跳”。我只能回答,这是科研,这是我热爱的事业,无论如何,我都会坚持下去。
最后,我要说,我们不能因为一次的失败就失去信心,“骄傲使人进步,自卑使人退步”。我希望所有在科研道路上奋斗的同行们,不要怕失败,不要畏难,要有“敢为人先”的精神,勇往直前,创造出更多的优秀成果。加油,我们在NeurIPS2023见!
发布于 2023-08-02 10:23・IP 属地新疆查看全文>>
Chat胡锡进 - 7 个点赞 👍
本文汇总了NeurIPS 2023中几篇与大模型或者预训练,in-context learning相关的文章
- In-Context Learning Unlocked for Diffusion Models
- PRODIGY: Enabling In-context Learning Over Graphs
- Optimizing Prompts for Text-to-Image Generation
- Can Language Models Solve Graph Problems in Natural Language?
- On the Planning Abilities of Large Language Models - A Critical Investigation
- Alternating Updates for Efficient Transformers
- Alignment with human representations supports robust few-shot learning
- On the Connection between Pre-training Data Diversity and Fine-tuning Robustness
- ID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets
- Continual Learning for Instruction Following from Realtime Feedback
- Conclusion
In-Context Learning Unlocked for Diffusion Models
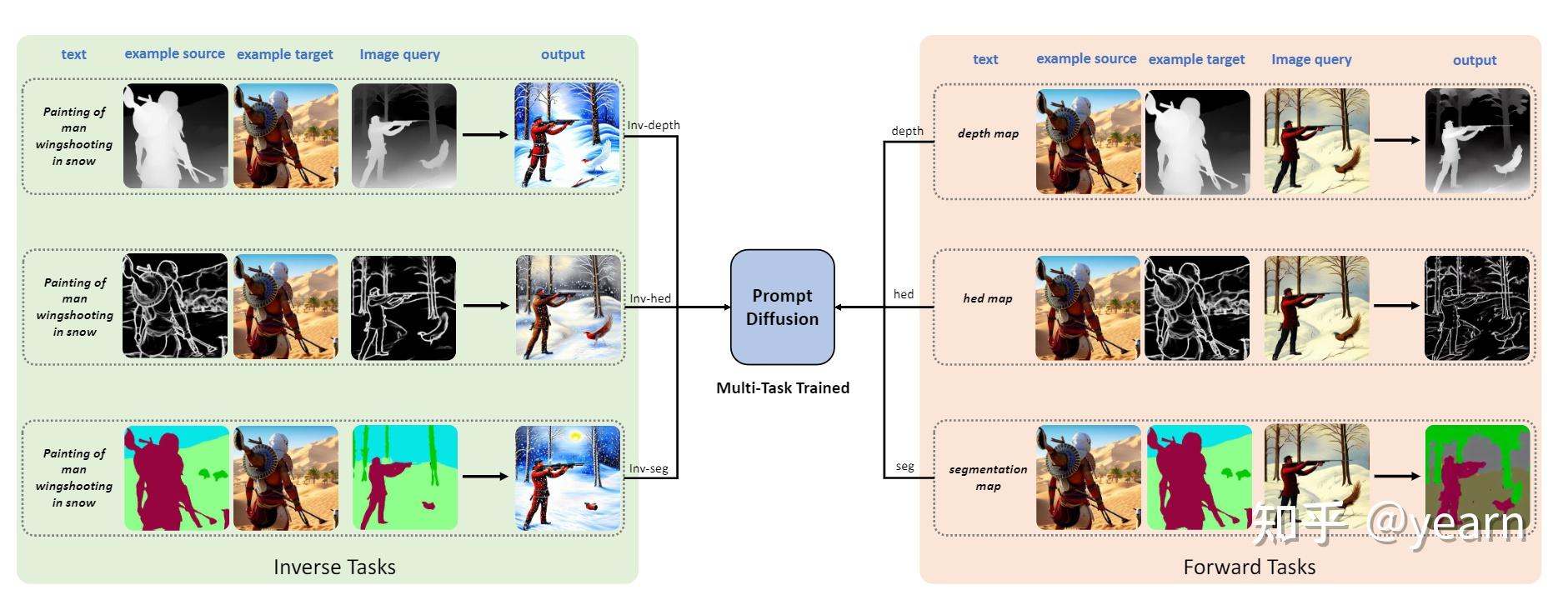
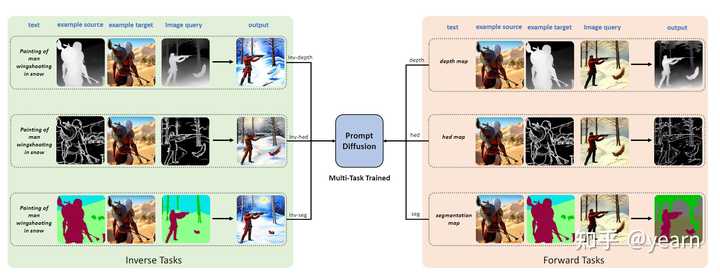
Motivation:NLP中in-context-learning取得了巨大的成功,但是对于大规模的视觉模型,有两个挑战制约了ICL的发展。(1)prompt的设计,对特定领域的输入输出,需要有有效的视觉prompt。(2)CV中大模型往往是为了特定任务训练了比如分割检测等。
这篇文章主要介绍了一种名为Prompt Diffusion的框架,用于在基于扩散模型的生成模型中实现上下文学习。该框架通过给定一对特定任务的示例图像和文本指导,自动理解底层任务,并根据文本指导在新的查询图像上执行相同的任务。
为了实现这一目标,作者提出了一种可以建模各种视觉-语言任务的视觉-语言提示,并将其作为输入传递给扩散模型。通过使用这些提示,扩散模型在六个不同的任务上进行联合训练。最终得到的Prompt Diffusion模型成为了第一个能够进行上下文学习的基于扩散的视觉-语言基础模型。该模型在训练任务上展示了高质量的上下文生成,并且通过各自的提示有效地推广到新的、未见过的视觉任务。该模型还展示了引人注目的文本引导图像编辑结果。该框架旨在促进计算机视觉领域的上下文学习研究。

PRODIGY: Enabling In-context Learning Over Graphs
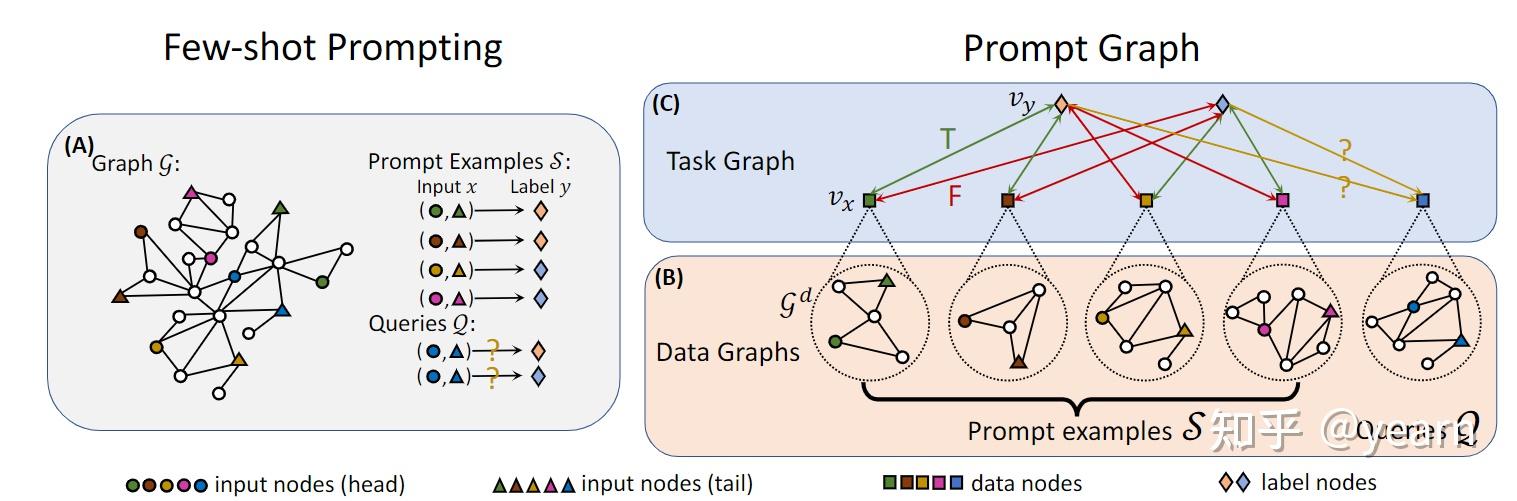
这篇文章介绍了一种名为PRODIGY的预训练框架,它可以实现在图上的上下文学习。文章指出,大型语言模型已经展示了在上下文学习方面的能力,但如何在图上进行上下文学习尚未被探索。PRODIGY的关键思想是使用一种新颖的提示图表示来构建图上的上下文学习,并提出了相应的图神经网络架构和一系列上下文预训练目标。通过PRODIGY,预训练模型可以通过上下文学习直接在未见过的图上执行新的下游分类任务。实验证据表明,PRODIGY在涉及引文网络和知识图谱的任务中具有强大的上下文学习性能。相比于硬编码适应的对比预训练基线,我们的方法平均提高了18%的上下文学习准确率。此外,相比于有限数据的标准微调,我们的方法平均提高了33%的上下文学习准确率。
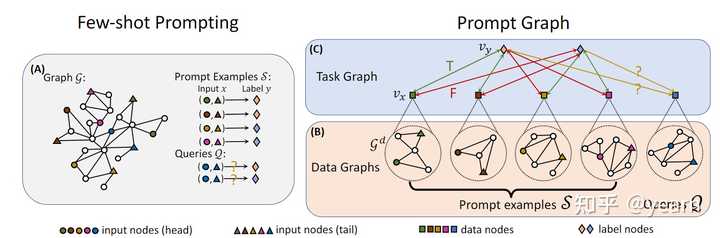

图1:在PRODIGY中使用图上下文的少样本提示的边分类的提示图。 (A) 给定源图G,我们提供了由输入头/尾节点及其标签以及查询组成的提示示例S。 (B) 对于来自提示示例和查询的每个数据点,我们首先通过从源图G中检索上下文来构造其数据图GD。 (C) 然后,我们创建一个任务图,以捕获每个数据点与每个标签之间的连接,其中包括每个数据点的数据节点vx和每个Y中的标签节点vy。 每对数据和标签节点都用与其二进制标签对应的边属性连接。 Optimizing Prompts for Text-to-Image Generation
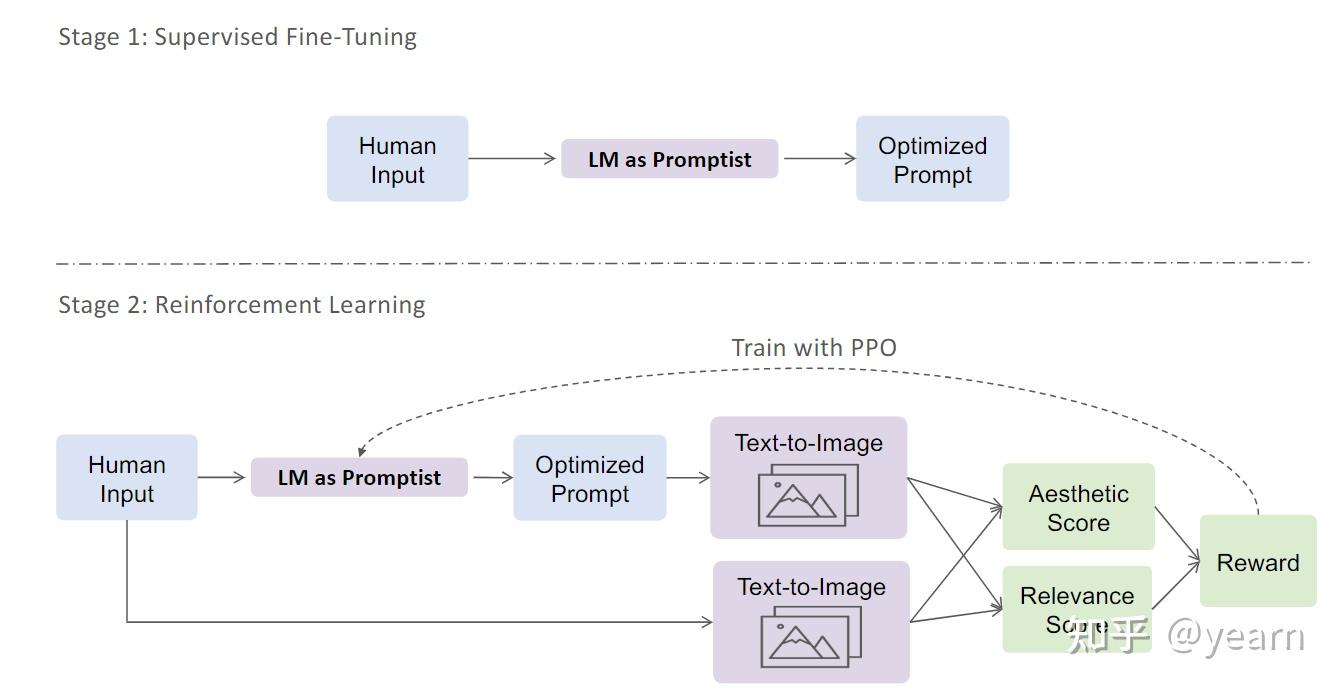
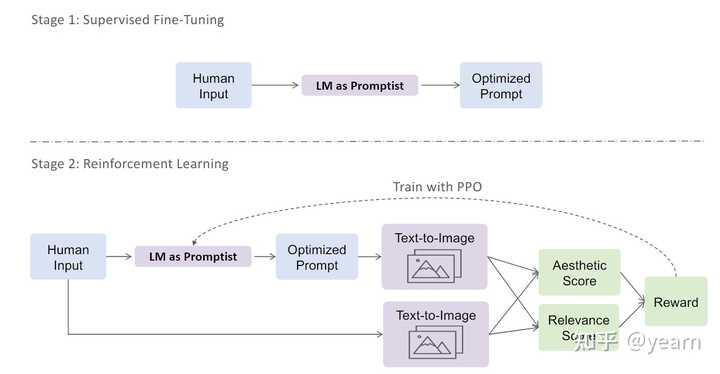
Motivation:现有工作在文本到图像生成中存在的主要缺陷是手动设计prompt的工作量大且耗时,并且往往无法适用于不同的模型版本。此外,手动设计的prompt往往无法很好地与用户意图对齐,导致生成的图像质量不高。这些缺陷启发了本文的研究,
这篇文章主要介绍了一种优化文本到图像生成prompt方法。作者提出了一个自动适应用户输入的提示框架,通过强化学习来探索更好的提示。首先,他们使用预训练语言模型对一小部分手动设计的提示进行监督微调。然后,他们使用强化学习来进一步优化提示。他们定义了一个奖励函数,鼓励模型生成更具美感的图像,同时保留原始用户意图。实验结果表明,他们的方法在自动评估指标和人类偏好评分方面优于手动设计的提示。此外,强化学习进一步提升了性能,特别是在领域外的提示上。

Can Language Models Solve Graph Problems in Natural Language?
LLMs越来越多地用于具有隐式图结构的任务,如机器人技术、结构化常识推理、多跳问题回答等,这表明需要其明确的图形推理能力。虽然LLMs在具有隐式结构的任务中表现出色,但其明确的图推理能力尚未充分探索。该论文旨在探讨LLMs是否能够使用自然语言在图上执行结构化操作。
- 基准创建:该论文引入了NLGraph基准,这是一个综合性的测试平台,用于评估LLMs的图推理能力。NLGraph包含29,370个问题,涵盖了各种图推理任务,涵盖了不同复杂性,从直观简单的任务,如连通性、循环和最短路径,到更复杂的问题,如拓扑排序、最大流、二部图匹配、哈密尔顿路径以及模拟图神经网络。
- 图推理评估:该研究使用不同的提示方法在NLGraph基准上评估LLMs,包括GPT-3/4。它检查LLMs在多种图推理任务中展现出的程度。
- 提示技术:研究探讨了各种提示技术,并评估其对LLMs的图推理的影响。它研究LLMs在使用不同提示的简单和复杂图推理任务中的性能。
- 基于指令的方法:该论文引入了两种基于指令的提示方法:构建图提示和算法提示。这些方法旨在通过提供具体的指令来增强LLMs在解决自然语言图形问题方面的能力。
- 性能改进:实验证明,构建图提示和算法提示成功提高了LLMs在图推理任务中的性能,性能提升幅度在多个任务中达到3.07%至16.85%。
尽管有所改进,使用LLMs解决最复杂的图推理问题仍然是未解的研究问题,突显了在这一领域进一步探索的必要性。论文承认LLMs具有初步的图形推理能力,对复杂任务中先进提示的影响减弱,存在在上下文学习中的挑战,以及LLMs对问题设置中的偶然相关性的敏感性。
On the Planning Abilities of Large Language Models - A Critical Investigation
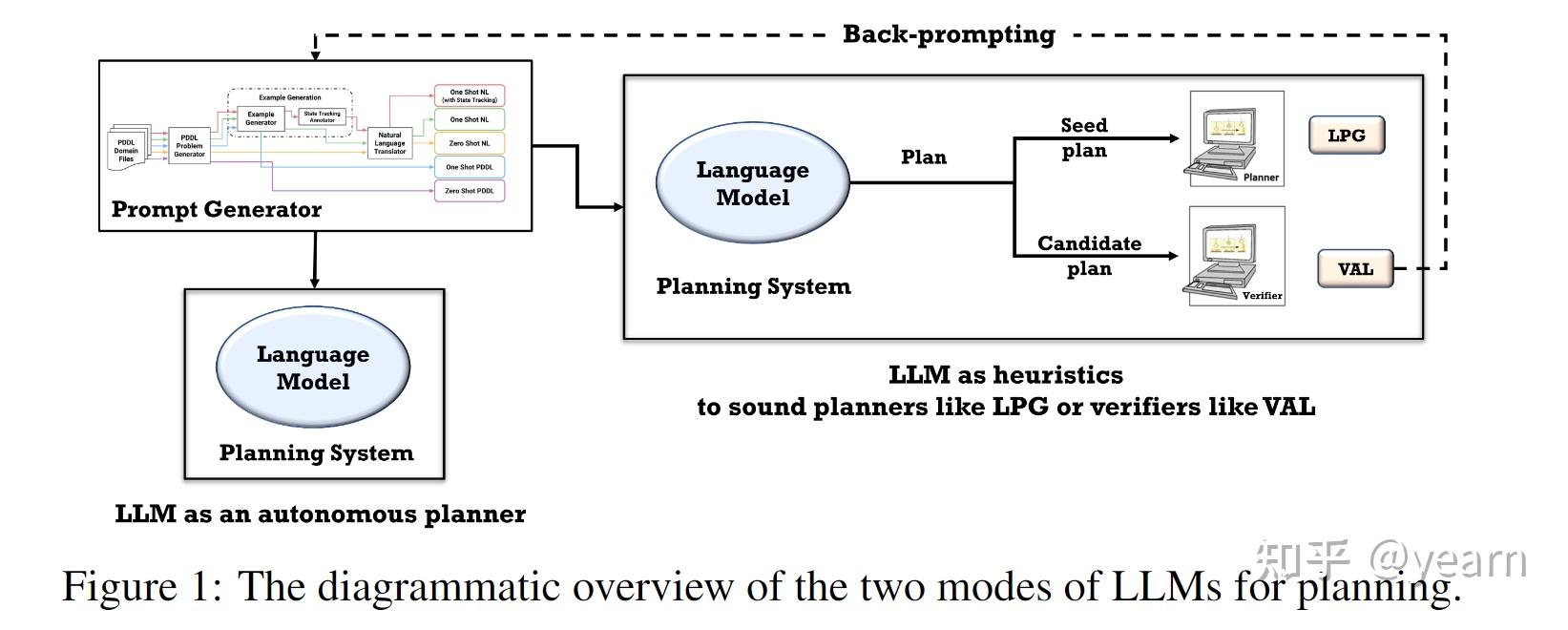
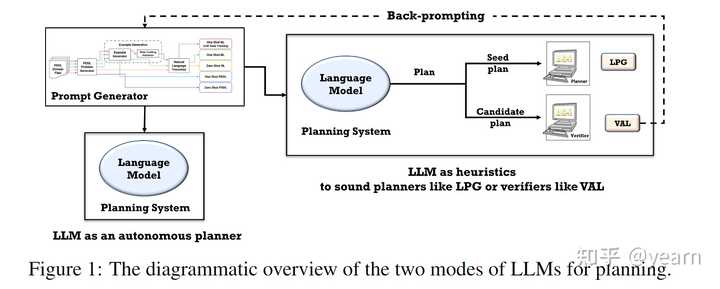
Motivation: 以往的工作在探索大型语言模型(LLMs)的规划能力方面存在以下问题:1. 以往的工作主要集中在常识领域/任务上,如在厨房中移动物品、婚礼/菜单规划等,这种评估方式并不包含关于特定领域的任何信息。因此,生成的计划很难评估,因为它们并不针对任何计划执行者,人们往往会对一个看似可行但实际上不可执行的计划给予reward。本文的研究则通过将领域作为提示的一部分来简化这个问题。2. 另一种评估规划能力的方式是用户与LLMs逐步交互,并重新提示LLMs指出其计划中的缺陷,希望LLMs最终能够生成可执行的计划。然而,这种评估方式实际上是由人类在交互中进行规划,而不是LLMs本身。因此,本文将评估分为自主模式和辅助模式,以明确LLMs的规划能力。3. 还有一些工作主要依赖LLMs作为将自然语言问题/目标规范转化为形式规范的“翻译器”,然后将其交给可靠的外部规划器。这种方法并不能揭示LLMs本身的内部规划能力,而本文的评估在自主模式和辅助模式下进行,可以更好地了解LLMs的规划能力。因此,本文的研究是由于以往工作中存在的评估问题而引发
这篇文章主要调查了大型语言模型(LLMs)的规划能力。研究者旨在评估LLMs在常识规划任务中自主生成计划的效果,以及LLMs作为启发式指导其他代理(AI规划器)进行规划任务的潜力。研究通过生成一系列与国际规划竞赛中使用的领域类似的实例,并以自主模式和启发式模式评估LLMs。研究结果显示,LLMs自主生成可执行计划的能力相当有限,最佳模型(GPT-4)在各个领域的平均成功率仅为12%。然而,在启发式模式下的结果显示更有希望。在启发式模式下,研究人员证明LLM生成的计划可以改善底层规划器的搜索过程,并且外部验证者可以帮助提供对生成计划的反馈,并促使LLM生成更好的计划。

Alternating Updates for Efficient Transformers
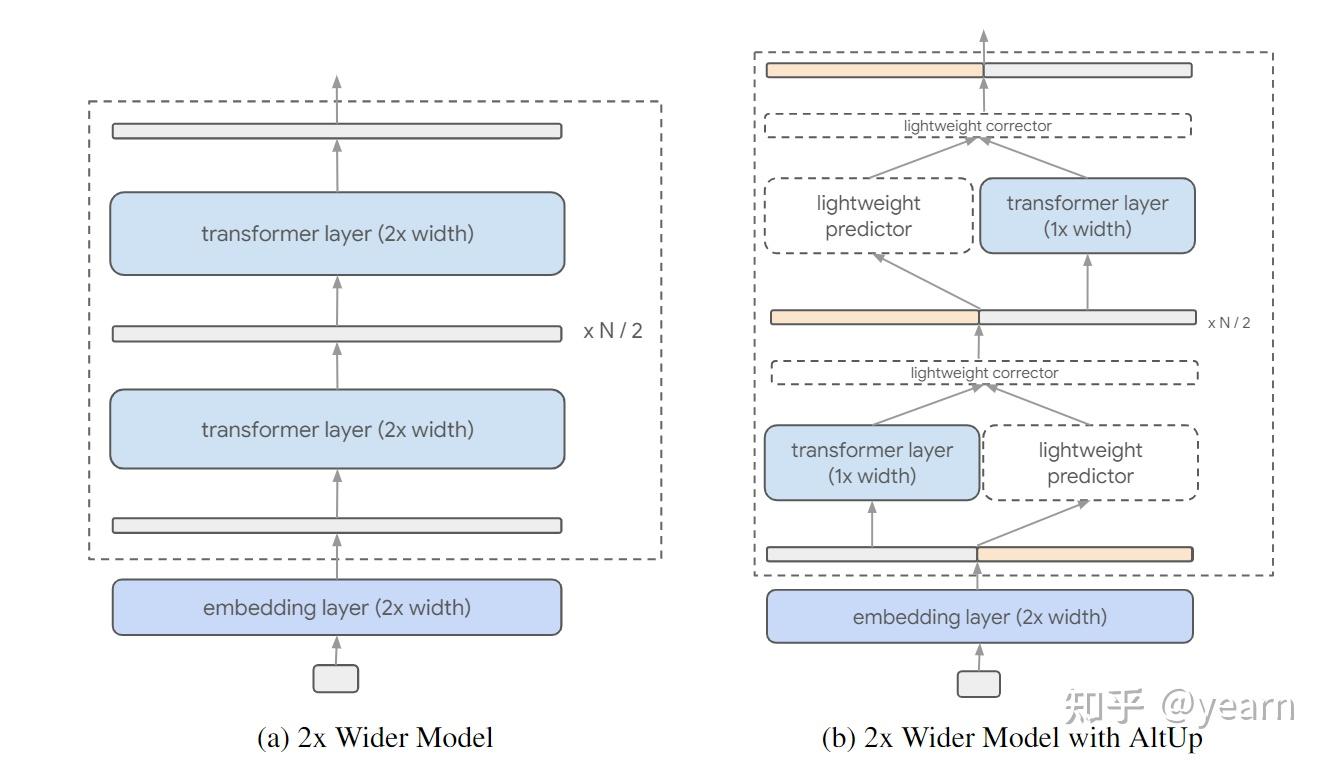
Motivation: 先前的方法主要关注于transformer的处理能力,而在高效地整合扩展的学习表示方面存在研究空白。最近的研究已经在实证和理论上证明,更宽的token表示(即更大的模型维度)有助于通过在表示向量中打包更多信息来学习更复杂的函数。然而,简单地扩展学习表示需要相应地增加模型维度,这会导致前馈计算量的平方级增加。因此,本文的研究目标是在不增加计算成本的情况下,通过引入交替更新(AltUp)技术,以一种简单高效的方式整合更宽的表示。
这篇文章介绍了一种名为Alternating Updates (AltUp)的技术,用于在Transformer模型中引入更宽的表示向量,以提高模型的性能。AltUp通过将扩展后的表示向量分成多个块,在每个Transformer层中只处理一个块,并使用高效的预测机制来推断其他块的输出。这样,AltUp能够保持模型维度和计算成本不变,同时利用增加的标记维度。与之前的方法相比,AltUp易于实现,需要较少的超参数调整,并且不需要分片。此外,AltUp专注于增加表示维度,可以与其他技术如Mixture-of-Experts (MoE)相结合,以获得互补的性能提升。
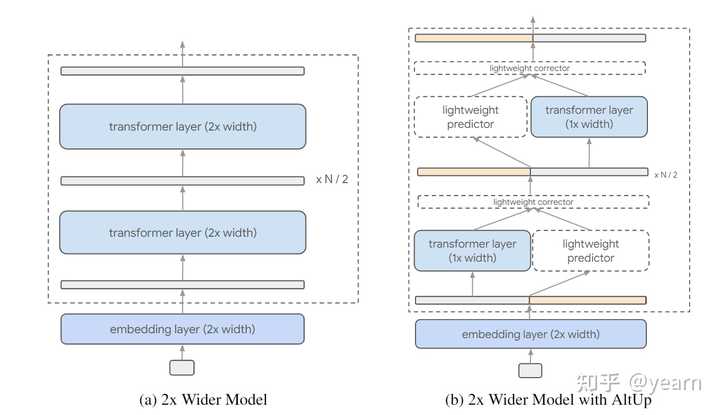

在不使用交替更新(左侧)和使用交替更新(右侧)的情况下,对token represnetation进行扩宽的示例。这种扩宽导致了在普通transformer中计算几乎呈平方增长,这是由于层宽度增加引起的。相反,交替更新保持层宽度不变,并通过在每一层上对表示的子块进行操作来高效地计算输出。 文章还介绍了AltUp的两个改进方法:Recycled-AltUp和Sequence-AltUp。Recycled-AltUp通过在最后一个线性+softmax操作之前将表示向量进行下投影,从而减少了计算量。Sequence-AltUp则通过对序列长度进行采样,只处理部分标记,从而减少了注意力机制的计算成本。
总的来说,这篇文章主要讨论了如何通过Alternating Updates技术来提高Transformer模型的效率,并介绍了两种改进方法。
Alignment with human representations supports robust few-shot learning
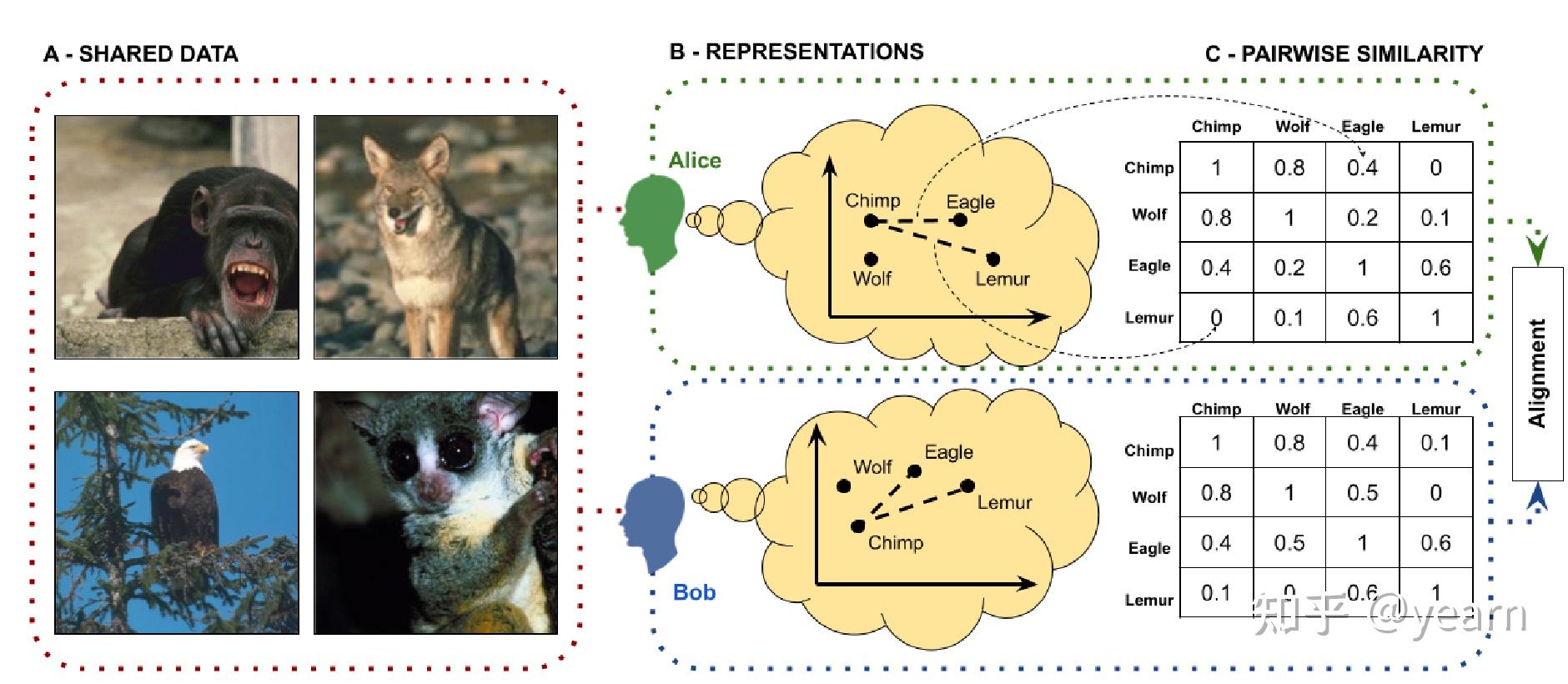
随着人工智能系统越来越多地融入涉及人类互动的环境中,调查这些系统在多大程度上与人类的表征相协调变得至关重要。以前的人工智能协调研究主要侧重于调整人工智能的value与人类的value(reward alignment),但本文强调了将人工智能系统的表征与人类的表征相协调的重要性。
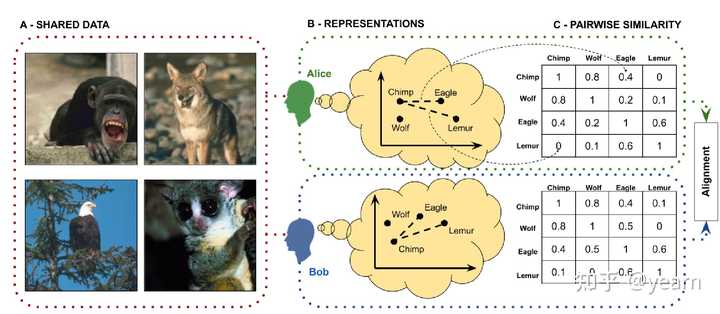

两个代理人Alice和Bob之间的表征协调示意图。A:共享数据(x)被展示给两位代理人。B:两位代理人分别形成观察到的对象的表征(f_A(x)和f_B(x))。C:代理人被要求生成与他们的表征相对应的成对相似性矩阵。然后可以比较相似性判断以测量代理人之间的协调程度。 表征协调:以与人类类似的方式表现世界被认为是人工智能系统能够表达共同价值、有效泛化和从有限数据中学习的重要前提。表征协调可以增强人工智能模型在实际应用中的性能。
信息论框架的开发:本文引入了一个信息论框架,用于分析表征协调对人工智能系统的影响。该框架提供了有关表征协调如何影响人工智能模型性能的见解,特别是在少样本学习任务中。
U形关系:理论框架预测表征与人类表征之间的程度与人工智能模型在少样本学习任务中的性能之间存在U形关系。这意味着与人类高度协调或表征相协调较低的模型可能表现优于表征中等协调的模型。
实证验证:为验证他们的预测并探索与表征协调相关的其他性质,本文使用了491个计算机视觉模型进行了实验。结果揭示了与人类协调的模型的三个重要性质:
- 与高度协调或低度协调的模型相比,中等协调模型在少样本学习任务中表现更好。
- 与自然对抗攻击相比,与人类协调的模型更加鲁棒
- 与领域变化相比,与人类协调的模型表现更加稳定
协调的充分性:本文指出,表征协调通常是实现人工智能模型有效利用有限数据、保持鲁棒性和良好泛化的充分但不是必要条件。
On the Connection between Pre-training Data Diversity and Fine-tuning Robustness
Motivation: 这篇论文旨在理解深度学习中预训练分布的属性如何影响微调模型的稳健性,特别是在自然分布转移的背景下。本文的主要动机和目标可以总结如下:
关键要点:
迁移学习和预训练:本文承认预训练在深度学习中提高模型性能的有效性,特别是在目标任务的数据有限时。像ImageNet这样的数据集的预训练已经成为各种计算机视觉任务的标准做法。
着重于Robustness:与以往主要关注模型准确性的研究不同,本文将焦点转向了在面对分布转移时微调模型的稳健性,这是在实际部署机器学习系统时的一个关键问题。
预训练分布的属性:本文旨在分析预训练分布的各种属性如何影响微调模型的稳健性。研究中调查的属性包括:
- 数据数量:在预训练中使用的数据数量。
- 标签空间:预训练期间使用的标签粒度。
- 标签语义:标签之间的语义相似性。
- 图像多样性:数据集内图像的多样性。
- 数据领域:用于预训练的数据来源。
数据数量的主要影响:根据实证结果,本文认为影响下游模型稳健性最显著的因素是预训练分布中的数据数量。数据数量的增加显著提高了稳健性。例如,即使使用来自ImageNet或iNaturalist的较小数据子集(25,000张图像)也会显著提高稳健性。
其他因素的影响有限:尽管数据数量是稳健性的主要驱动因素,但本文发现标签粒度、标签语义和图像多样性的变化对稳健性影响较小。极端减少标签粒度或包括更多语义相似的类别并不显著影响微调模型的稳健性。
数据来源的重要性:本文还研究了不同的预训练数据来源,包括自然数据和合成数据集。在数据数量受控的情况下,自然数据来源(如ImageNet和iNaturalist)在下游稳健性方面表现相似。此外,合成预训练数据,如合成的fractal 数据,相对于从头开始训练,提供了一些稳健性增益,但不如自然数据明显。
ID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets
这篇论文的动机在于研究深度学习模型的内部分布(ID)与外部分布(OOD)性能之间的关系,特别关注它们在真实世界数据集上的逆相关关系。论文旨在解决逆相关关系的实证证据不足的问题,尽管从理论上讲,这种逆相关关系是可能存在的。它试图探索为什么以及何时ID和OOD性能会呈现逆相关关系,以及过去的研究可能如何忽略了这些关系。
研究发现:
- 论文呈现了实证证据,证明在真实世界的数据集中ID和OOD性能之间存在逆相关关系,而不仅仅存在于人为最坏情况的情境中。
- 论文理论上解释了逆相关关系是如何发生的,以及过去的研究可能由于方法偏差而未能识别这些关系。
研究结果的含义:
- 达到高OOD性能有时需要与ID性能进行权衡。这意味着在OOD任务中表现出色的模型可能在ID任务上表现较差,反之亦然。
- 仅专注于优化ID性能可能不会导致最佳OOD性能。论文提出,集中精力进行ID泛化可能会导致OOD性能的递减或负面回报。
- 在OOD泛化研究中使用ID性能进行模型选择的常见做法可能导致一个盲点。这可能会忽视那些在OOD性能方面表现最佳的模型,从而忽略了机器学习中的一系列现象。
逆相关关系的解释:
- 论文引入了“误规范化”的概念,作为“欠规范化”的扩展,以解释为什么在ID性能相似的模型中,OOD性能可能会有显著差异。在误规范化的情况下,用于训练模型的经验风险最小化(ERM)目标与最大化ID性能一致,但与实现高OOD性能发生冲突。因此,ID和OOD指标呈现逆相关关系。
- 数据中健壮特性和虚假特性(robust and spurious)的存在有助于逆相关关系的出现。根据分布变化的幅度,观察到不同的ID和OOD性能模式。
Continual Learning for Instruction Following from Realtime Feedback
这篇论文的动机是解决通过互动中的实时用户反馈改进instruction-following agent的挑战。作者旨在利用用户提供的反馈,特别是二进制信号的形式,来不断训练代理。动机可以总结如下:
语言学习信号: 人类用户和自动代理之间的语境化语言互动提供了有价值的语言学习信号。用户在指导代理执行任务时提供明确的反馈。
学习范式转变: 这种方法将学习范式从仅依赖注释数据转变为通过用户互动学习。这降低了数据成本,允许通过与用户的持续互动实现持续改进。
反馈与演示: 与使用演示数据的传统方法不同,这种方法侧重于用户反馈,直接针对代理的当前行为。它与代理的当前策略更相关。
通过互动学习: 本文旨在通过与用户的持续互动来弥合训练和部署之间的鸿沟。但是这些信号由用户实时提供,可能是嘈杂和不可预测的,因此作者了提出了特殊的设计来克服这个困难。
Conclusion
这些spotlight,囊括了将ICL拓展到多模态大模型,图模型的方法,还有很大程度一部分单纯的试验工作,去揭示目前大模型存在的一些问题,可以看到LLM虽然火热,但是遗留下来的问题也相当多,如何在其他领域复刻LLM的成功,以及更好的预训练数据/方式仍然是一个open question.
最后,欢迎大家关注github,聚合了OOD,causality,robustness,optimization以及一些前沿研究方向的一些阅读笔记,非常欢迎大家补充完善
发布于 2023-11-17 12:57・IP 属地北京查看全文>>
yearn - 5 个点赞 👍
查看全文>>
快乐牛仔 - 0 个点赞 👍


NeurIPS,全称Annual Conference on Neural Information Processing Systems,是机器学习领域的顶级会议,与ICML,ICLR并称为机器学习领域难度最大,水平最高,影响力最强的会议!NeurIPS是CCF 推荐A类会议,Core Conference Ranking推荐A*类会议,H5 index高达278!NeurIPS是由连接学派神经网络的学者于1987年在加拿大创办,后来随着影响力逐步扩大,也曾移师美洲、欧洲等地举办。早年发布在NIPS中的论文包罗万象,从单纯的工程问题到使用计算机模型来理解生物神经元系统等各种主题。但论文的主题主要以机器学习,人工智能和统计学为主。
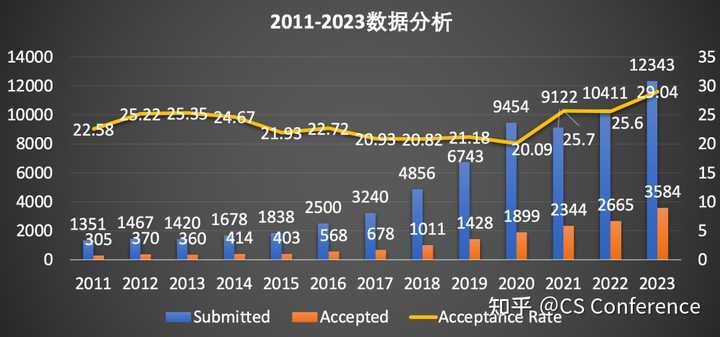

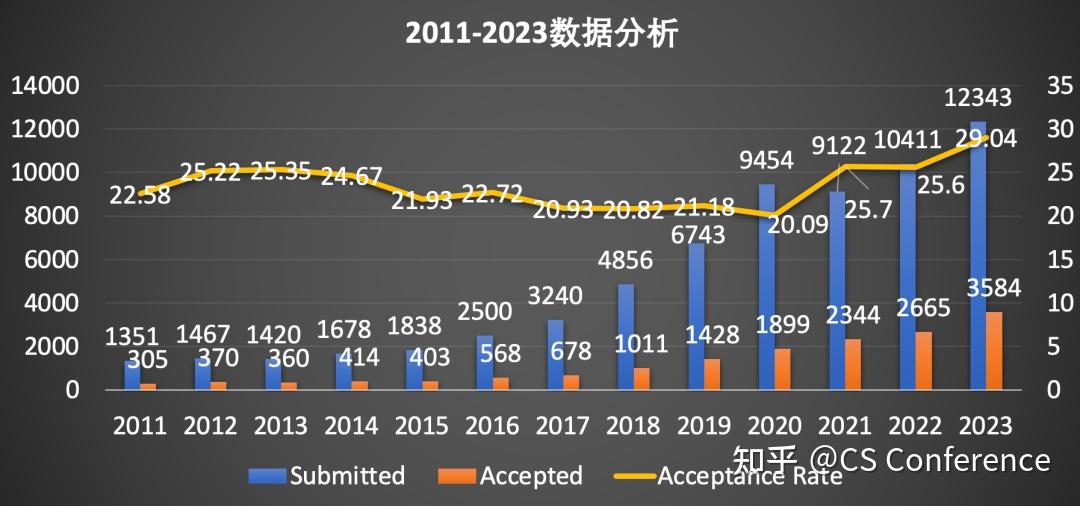
NeurIPS的录取率相对稳定,在20%-30%之间,由于21年增至25.7%,今年更是增长到29.04%,达到近10年来的历史最高纪录!较高的录取率导致很多学者都想把AAAI,IJCAI等拒稿的会议投NeurIPS了,不过NeurIPS对文章的要求,整体来讲还是要比AAAI与IJCAI等高一个档次。从投稿量来看,NeurIPS的投稿量从2016年开始出现大幅上升,而且是近乎指数的上升,2022年成功突破10000篇,2023年则是投稿数量再创新高,为12343篇。从录取量来看,NeurIPS的录取量也是逐年上升,今年更是突破3000篇!
NeurIPS'23
组委会信息
今年的NeurIPS将再一次在美国新奥尔良召开,时间为12月10日-16日,地点与去年会议举办地相同。目前官网只公布了Organizing Committee的信息,Programming Committee还没有公布,在Organizing Committee中,国内只有来自台湾的Hsuan-Tien Lin (National Taiwan University)担任Workshop Chair,希望能在Programming Committee中能够看到更多国内学者的身影。


NeurIPS'23官网链接: https://nips.cc/Conferences/2023
主旨演讲
NeurIPS2023会议共计筹划了七场演讲,从12月11日一直持续到12月14日。目前已经公布的演讲主题如下:
- NextGenAI: The Delusion of Scaling and the Future of Generative AI
- The Many Faces of Responsible AI
- Coherence statistics, self-generated experience and why young humans are much smarter than current AI


来自清华大学的唐杰教授也会参与到其中一场Panel中(官网有误),为多人参与,更多细节目前暂未公布。


注册费信息
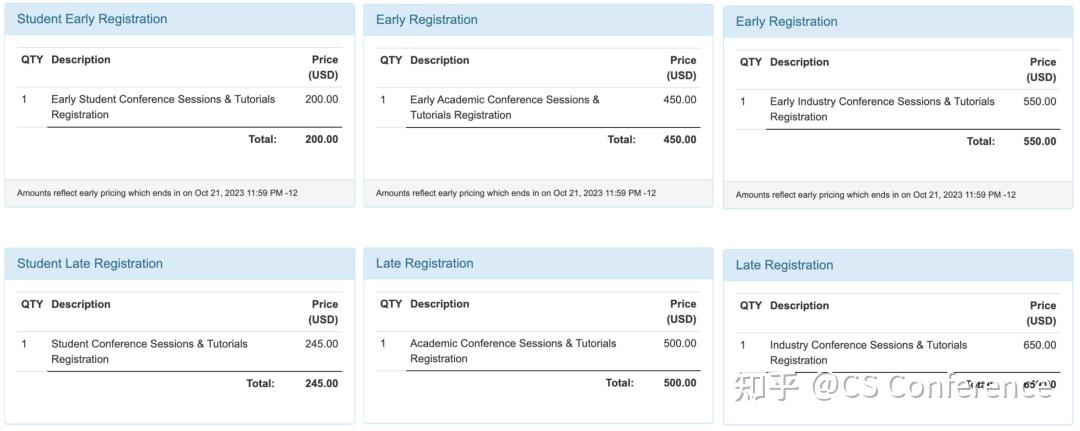
NeurIPS 2023会议将在线下召开,会议注册包括线下参会和虚拟参会两种类型。其中学生虚拟参会仅需50刀,而工业界参会价格最高,线下参加需要550刀,具体明细如下:
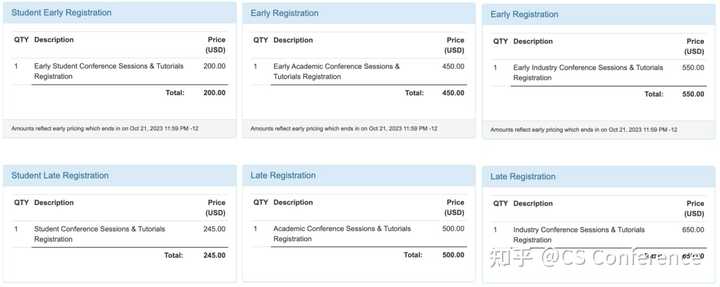

更多价格选项可以查询:
https://nips.cc/Conferences/2023/Pricing
录用信息
本届NeurIPS共收录文章3584篇,因为接收量较大,因此这里暂不一一列出,感兴趣的读者可以通过链接访问:
发布于 2023-11-12 11:21・IP 属地北京查看全文>>
CS Conference