
本文是《2023大模型产业发展白皮书》为未完成稿,作者:王文广,两个孩子的爸爸。欢迎各种合作!
大模型太卷了,卷大模型最关键的还是商业落地:
第一章 大模型技术要点
人工智能(Artificial Intelligence,AI)是指由计算机系统或机器执行的智能行为,如学习、推理、感知、创造等。人工智能在各个领域都有广泛的应用,如医疗、工业、教育、金融、安全、娱乐、交通、营销等等。人工智能也是当今世界最具创新性和竞争力的技术之一,对于提升国家的科技实力和经济发展有着重要的意义。
人工智能大模型(Large Models)即神经网络预训练大模型,通常简称为“大模型”,是一种基于深度学习的人工智能技术。其核心思想是将模型使用大量的计算资源,通过深度学习等方法在大规模数据集上进行预训练,使其学会一般性的特征表示、知识和语言模式,训练出具有强大的泛化能力和表达能力的人工智能模型,然后通过微调适应特定任务。
人工智能大模型可以处理多种类型和规模的数据,如文本、图像、音频、视频等,可以完成多种复杂和高级的任务,如自然语言理解、计算机视觉、语音识别、自然语言生成等。自2022年11月30日 ChatGPT 发布以来,人工智能大模型通常是指以语言为核心的大语言模型(Large Language Models)或者多模态大模型(Multi-Modal Models),是当前人工智能领域炙手可热的研究方向,形成了一种新的人工智能范式,也被认为是实现通用人工智能(AGI)的最可行的路径。
1.1 预训练+微调的技术方案
大模型通常采用预训练+微调(Pre-training+Fine-tuning)作为基本的模型方法,以提高模型的通用性、适应性、有用性和安全性。例如,GPT-3首先在大规模的文本数据上进行无监督的预训练,学习通用的语言知识和表示,然后在特定的任务数据上进行有监督的微调,学习特定的任务知识和技能。同时还是用人类反馈的强化学习来对齐价值观,确保更好的安全性。
预训练是大模型的第一阶段,模型在大规模数据集上进行训练,学会语言结构、语法、常识等一般性的信息和知识。这个阶段的模型并不是针对特定任务进行优化,而是学习如何从数据中提取有用的特征。 大模型需要使用海量的数据来进行预训练,以提高模型的性能和泛化能力。例如,GPT-3是目前世界上最大的自然语言处理(NLP)模型,它使用了约1750亿个参数,并使用了45TB的文本数据来训练。 大模型的第二阶段是微调,模型在特定任务的数据集上进行微调,以适应具体任务的要求。这种预训练与微调的融合,使得大模型在少量任务数据下就能取得出色的表现。
1.2 先进的网络结构
大模型通常拥有深层的神经网络结构,例如 GPT-3用来93层的 变换器网络(Transformer)的解码器(Decoder)块。由于网络层数的增加,模型能够学习更加抽象和高级的特征表示。为了训练这些大模型,需要大量的计算资源,包括高性能的硬件和优化的训练算法。这些资源的结合使得大模型的训练成为可能,同时也为其带来了强大的泛化性、通用性和实用性。
人工智能大模型通常采用Transformer作为基本的网络结构,使用了自注意力(Self-Attention)机制来捕捉长距离的依赖关系。
1.3 需要强大的计算资源来支撑
人工智能大模型需要使用强大的计算资源来训练,以缩短训练时间和提高训练效率。例如, LLaMA-2-70B 的大模型,使用了2000个Nvidia A100 GPU的分布式超级计算集群来训练,耗费了1720320 小时的A100 GPU计算量(2000个 A100 GPU,约35天)。Falcon-180B大模型,使用了4096个Nvidia A100 GPU,耗费了约700万 GPU 时。
1.4 大模型的量化技术
量化是一种能够有效减少大模型计算和存储开销,降低大模型的部署成本和推理延迟的技术,其核心思想是通过减少每个参数和激活的位数,来压缩模型的大小和加速模型的运算。量化的基本思想是将连续的浮点数映射到离散的整数,例如将32位浮点数转换为8位整数。这样,每个参数和激活就可以用8个比特来表示,从而实现4倍的模型压缩和运算加速。然而,量化也会引入一定的误差,导致模型的精度下降。因此,如何在保证模型精度的同时,实现高效的量化,是一个具有挑战性的问题。
目前,主要有两种量化的方法:后训练量化(Post-Training Quantization, PTQ)和量化感知训练(Quantization-Aware Training, QAT)。PTQ是指在模型训练完成后,直接对模型的参数和激活进行量化,不需要额外的训练过程。QAT是指在模型训练的过程中,对模型的参数和激活进行量化,并通过反向传播来更新量化的参数,以减少量化误差。PTQ的优点是简单和快速,不需要额外的计算资源,但是在低位数的量化下,模型的精度会显著下降。QAT的优点是可以保持较高的模型精度,甚至在低于8位的量化下,但是需要重新训练模型,消耗大量的计算资源。
针对LLM的量化,目前的研究主要集中在PTQ上,因为QAT对于LLM来说,需要的训练时间和成本太高。然而,PTQ也面临着一些挑战,主要是由于LLM中的激活存在一些异常值(outliers),这些异常值会影响量化的范围和精度,导致量化后的模型性能下降。为了解决这个问题,一些方法提出了对激活进行变换或重组,以减少异常值的影响。例如,SmoothQuant提出了一种数学等价的变换,将激活的异常值转移到权重上,从而实现了8位权重和8位激活(W8A8)的量化,同时保持了模型的精度。QLLM提出了一种自适应的通道重组技术,将激活的异常值分配到其他通道上,从而平衡了激活的分布,实现了4位权重和4位激活(W4A4)的量化,同时超越了之前的最优方法。Outlier Suppression+提出了一种针对不对称性的通道式移位和针对浓度的通道式缩放的方法,将激活的异常值压缩到量化的范围内,实现了实现更好的量化负担平衡,保持了模型的精度。
除了对激活进行处理,一些方法还提出了对量化后的模型进行微调,以补偿量化误差。例如,LLM-QAT提出了一种无数据的量化感知训练方法,只学习一小部分低秩的权重,而冻结预训练的量化模型。在训练后,这些低秩的参数可以与冻结的权重融合,不影响推理。大模型的量化是一种有前景且非常有价值的技术,它可以降低大模型的部署成本和推理延迟,减少推理过程中所需要的计算量,从而促进大模型的普及和应用,并在减少碳排放实现碳中和目标中提供支持。当前,大模型量化的研究,集中在如何设计更高效和更通用的激活变换或重组方法,以适应不同的大模型和不同的量化位数。
1.5 大模型蒸馏技术
大模型蒸馏的基本思想是使用一个大的教师模型(teacher model)来指导一个小的学生模型(student model)的学习,使得学生模型能够从教师模型中吸收有效的知识,实现接近与教师模型的性能和泛化能力。模型蒸馏的优点是可以利用大模型的强大能力,同时减少模型的规模和复杂度,提高模型的效率和可部署性,这对于需要巨大计算量支持的超大模型来说非常有用,可以大幅减少推理成本。模型蒸馏的挑战是如何设计合适的学生模型和损失函数,以及如何选择合适的训练数据集,以保证学生模型能够最大程度地从教师模型中学习到有用的知识,而不是过拟合或者欠拟合。
1.6 泛化能力和跨领域迁移能力的突破性提升
大模型在经过预训练后,展现出惊人的泛化能力。即使在只有少量任务数据的情况下,它们能够理解并适应任务的上下文、要求和特点。这为许多应用场景带来了巨大便利,无需大量数据的情况下,就能快速构建高性能的人工智能应用。
大模型的技术在多个领域都取得了突破性的性能提升。在自然语言处理领域,大模型在机器翻译、文本生成、情感分析等任务上都表现出色,达到甚至超越人类水平的表现。在计算机视觉领域,大模型在图像分类、物体检测、图像生成等任务中也取得了重大进展。智能语音领域的语音识别、语音生成等任务也因大模型技术而得以显著提升。

第二章 人工智能技术简史
人工智能从上世纪五十年代开始,至今已经有七、八十年的历史了。
2.1人工智能萌芽期
1950年代之前:理论萌芽与思想奠基 在人工智能概念之前,1950年,图灵( Alan Turing )在论文《Computing Machinery and Intelligence 》提出了图灵测试的概念,认为如果机器表现的像人类,那么它就跟人类一样智能。比如和一个机器人聊天,当你无法分辨出对方是机器人的话,那么就可以认为那个机器人跟人一样智能。

1950年代前后,工智能的奠基工作开始,符号主义的逻辑推理引擎等是当时的焦点,它们能够解决数学问题并进行逻辑推理。这个时期的代表性成果是人工智能三大范式的诞生,即:
- 联结主义,神经元,1943年Pitts 等发表了论文《A logical calculus of the ideas immanent in nervous activity》
- 行为主义,控制论,1948年维纳出版了书籍《Cybernetics: Or Control and Communication in the Animal and the Machine》
- 符号主义,逻辑理论家,1955年艾伦·纽厄尔等编写了"Logic Theorist"程序,被成为史上第一个人工智能程序,证明了在怀特黑德和罗素合作撰写的数学原理中首52个定理中的38个。
2.2 人工智能诞生期
1956年的达特茅斯会议上,麦卡锡、明斯基、香农等逻辑学家在达特茅斯学院召开的会议中,提出了人工智能(Artificial Intelligence)的概念。
时间来到1960年年代,符号主义继续发展,知识表示与专家系统逐渐兴起。人工智能开始关注如何将知识编码到计算机中,以便解决特定领域的问题。DENDRAL等专家系统将领域专家的知识转化为计算机可执行的规则,并得到了极大的发展,在此后的七八十年代大放异彩。
2.3 人工智能的第一个冬天
1970年代初,人工智能开始了第一个冬天,原因包括XOR 异或问题无法解决,自动翻译遇到了巨大的困难,逻辑的方法遭遇了危机。在1970年代末,反向传播算法被提出,人工智能慢慢走出低谷。
2.4 冬天过后的繁荣期
到了1980年代,知识是当时的绝对主角,专家系统崛起,CYC、WordNet 等许多本体库被构建,人们认为列出所有存在的事物,并构建一个本体描述我们的世界是智能系统的基础。这个观点促使了知识和逻辑的结合,并使得专家系统达到鼎盛,被应用于医疗、金融等等诸多领域。
计算机的能力开始迅速的提升,机器学习开始复兴,支持向量机(SVM)和决策树等方法为数据驱动的机器学习奠定了基础。同时,强化学习中的马尔可夫决策过程(MDP)框架为智能体与环境的交互提供了理论基础。而机器学习和符号主义的结合,IBM 的深蓝击败了国际象棋世界冠军为这一波人工智能的巅峰添加了浓墨重彩的一笔。知识的表示发展到了语义网的阶段,大量的知识和复杂的逻辑相结合过于复杂而无法实用。
2.5 人工智能的第二个冬天
1980年代末到1990年代初,专家系统的维护成本高昂导致人们逐渐对齐失去了兴趣,人工智能逐渐冷却,形成了第二个冬天。
2.6 统计学习的兴起
1990年代~2000年代属于摩尔定律和互联网高速发展的时期,人工智能依附于互联网开始积蓄力量。由于语料的增长,统计学习在这个时期迅速发展,贝叶斯网络、隐马尔可夫模型、信息论、神经网络、SVM 等算法喷涌而出。马尔可夫决策过程和控制论的结合,形成了一种称之为智能体(Agent) 的新思想,具身智能开始发展。
2.7 认知智能时代
2000年代末期,由于计算机算力的发展和互联网带来的数据增长,神经网络以深度学习的概念重新崛起,并逐渐成为了人工智能的主角。深度网络(多层神经网络)能够从大量数据中学习复杂模式,在语音识别、图像识别与理解中 得到广泛应用。
2010年代开始,一方面,符号主义的RDF、本体和逻辑以知识图谱的形势重新回归,知识的表示与推理高速发展;另一方面,大数据和大算力的组合,推动着深度学习迈向大规模预训练模型(如 BERT、GPT 等)时代。知识图谱和深度学习共同推动着人工智能的高速发展,迈向了认知智能时代。
2.8 迈向通用人工智能
2020年代伊始,以ChatGPT 为代表的大规模预训练语言模型展现出了强大的理解能力,并为通用人工智能 AGI 带来了第一缕曙光,也因此,伦理、隐私和社会影响等问题也日益受到关注,为技术的发展与应用提出了新的挑战。

第三章 大模型发展情况
人工智能大模型目前发展的情况是美国遥遥领先,中国紧跟其后。在核心技术方面,主要的创新由 Google(包括 DeepMind)、 OpenAI、 微软、Meta 等公司和斯坦福、伯克利等高校为主。中国的清华大学、浙江大学、北京智源研究院、上海人工智能实验室以及百度、华为等也有所贡献。
3.1 开源基础大模型
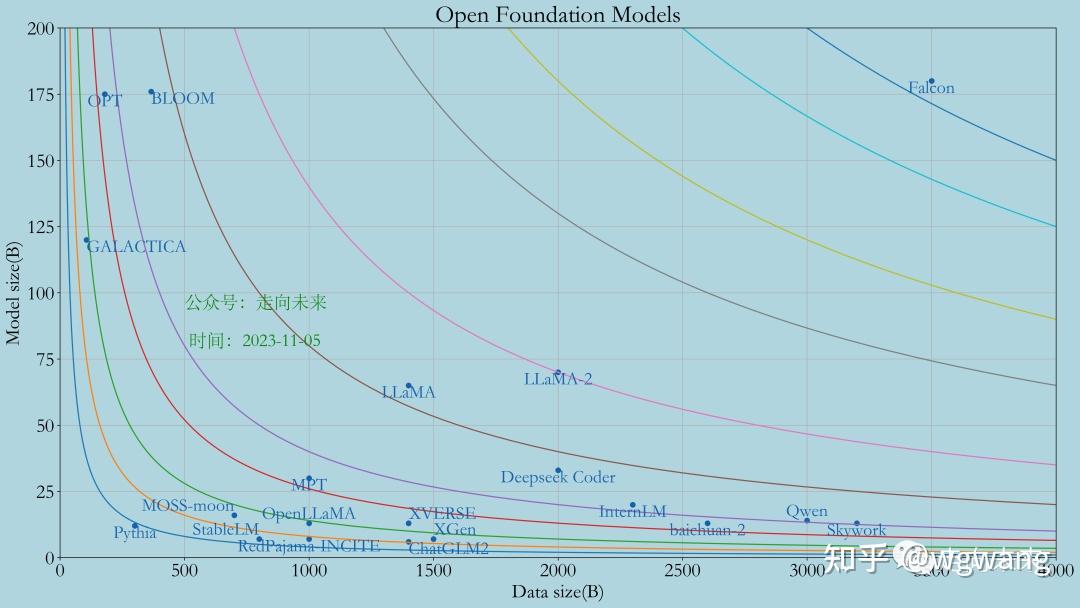
下面是开源基础大模型全解析,未完全: LLaMA:开源开放大模型观察之LLaMA
LLaMA2:开源开放大模型全观察之LLaMA-2
Baichuan:开源开放大模型观察之baichuan-7B
Baichuan2:开源开放大模型全观察之Baichuan-2
BLOOM:深度全解析开放开源大模型之BLOOM
QWen:开源开放大模型全观察之QWen
Falcon:开源开放大模型全观察之Falcon
3.2 国外大模型测试与点评
-ChatGPT:AGI生成式AI面试题目解析、全面面试ChatGPT及专业点评,大模型的差距看得见系列之一
-Bing Chat:全面面试Bing Chat及专业点评,大模型的差距看得见系列之二
-Google Bard:全面面试 Google Bard和Claude2及专业点评,大模型的差距看得见系列之三
-Anthropic Claude:全面面试 Google Bard和Claude2及专业点评,大模型的差距看得见系列之三
-LLaMA-2:全面面试LLaMA-2、WizardMath和CodeLLaMA及专业点评,大模型的差距看得见系列之四
3.3 国外领军大模型一览表
| 公司 | 大模型 | 说明 |
| OpenAI | ChatGPT | ChatGPT-4支持Plugins,Code Interpreter |
| 微软 | Bing Chat | 搜索增强,有三种模式 |
| PaLM2,Bard,Gemini | Bard支持图片内容识别,包括OCR等 | |
| Anthropic | Claude | Claude 2,支持读入pdf、txt、csv等文件进行分析、总结和问答等 |
| Meta | LLaMA,LLaMA-2, CodeLLaMA | 最强开源开放大模型,月活用户小于7亿的组织和个人可随意商用 |
| Stability AI | StableLM | |
| Amazon | Titan | |
| Bloomberg | BloombergGPT | |
| MosaicML | MPT | |
| Intel | Aurora genAI | |
| UC Berkeley, Microsoft Research | Gorilla | |
| inflection.ai | Inflection-1 | |
| xAI | Grōk | 从OpenAI 到xAI |
| cohere | Cohere | |
| Scale AI | Scale | |
| character ai | Character | |
| Colossal-AI | ColossalChat | |
| Nvidia | ChipNeMo |
其中,国外大模型的详细分析:
Gemini : 值得关注的Google下一代通用人工智能双子座Gemini系统
xAI:我为什么创办xAI?马斯克自述从OpenAI到xAI的心路历程

第四章 国产大模型深度分析
从模型本身角度,中国可谓是热火朝天,百模大战不是盖的。截至今天,中国已发布的大模型有188个。数据来自“微信公众号:走向未来”收集,原始数据存放于“Github :https://github.com/wgwang/LLMs-In-China”。欢迎评论提供缺失遗漏的国产大模型。
4.1 国产大模型地图分布
在这188个大模型中,按省份进行统计,并用地图可视化出来,如下图所示,可以清楚地看出,祖国山河几乎一片红,特别是东部沿海地区的省市都有机构发布了大模型。按省级单位来说,这188个大模型分布于23个省级单位(包括自治区、直辖市和特别行政区)。
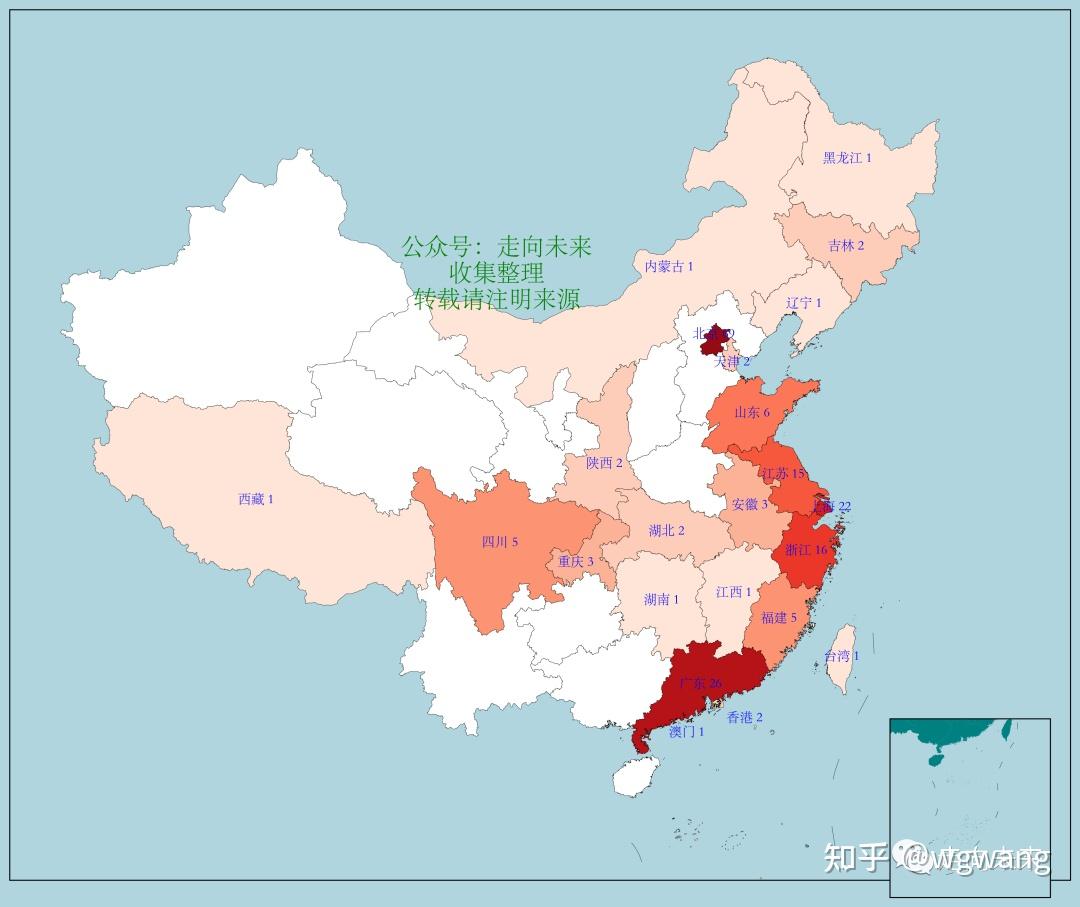
其中,有3个或更多的机构发布了大模型的省和直辖市有10个,这些省市如下所示:
| 序号 | 省级单位 | 大模型个数 |
| 1 | 北京 | 69 |
| 2 | 广东 | 26 |
| 3 | 上海 | 22 |
| 4 | 浙江 | 16 |
| 5 | 江苏 | 15 |
| 6 | 山东 | 6 |
| 7 | 四川 | 5 |
| 8 | 福建 | 5 |
| 9 | 安徽 | 3 |
| 10 | 重庆 | 3 |
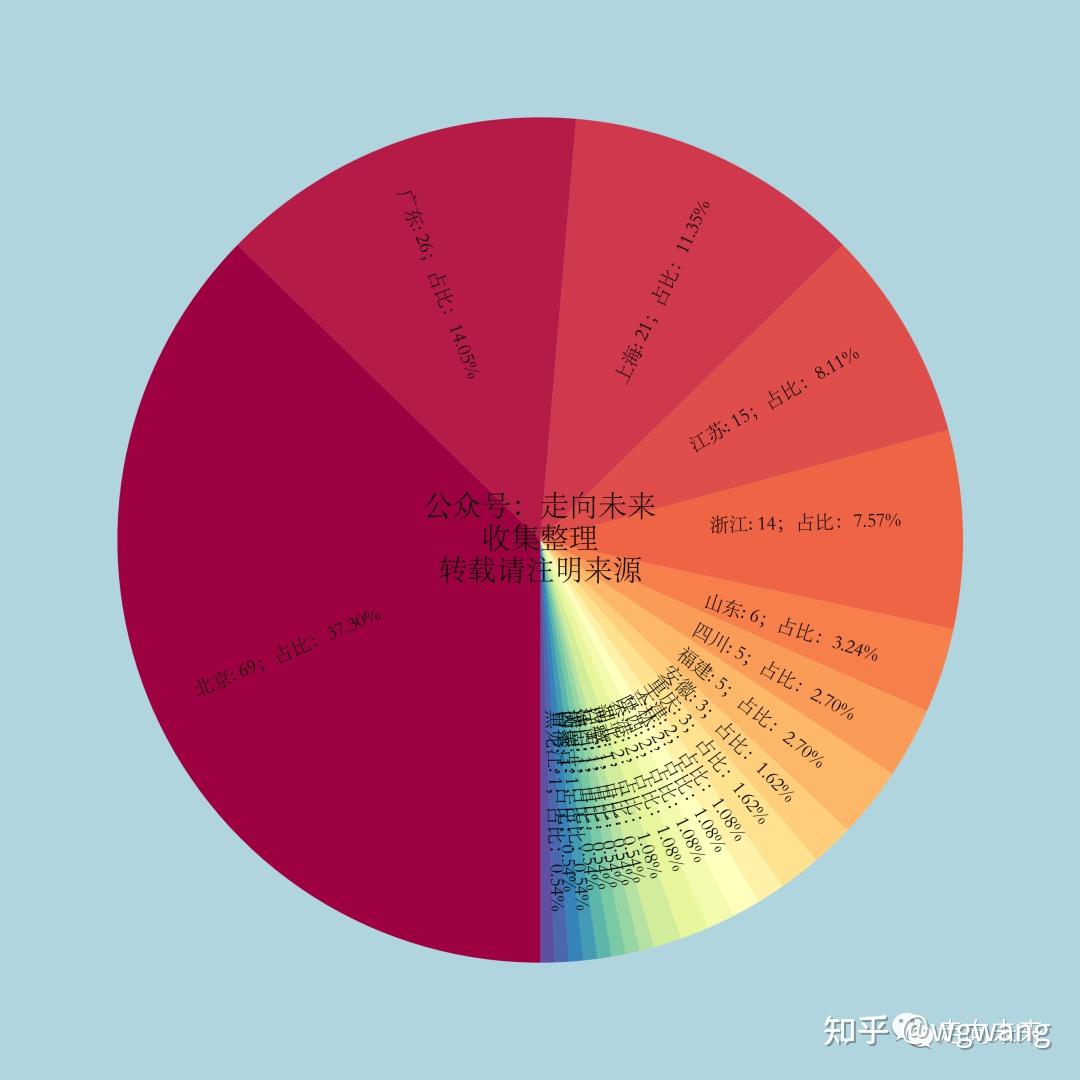
各个省级区划的占比如下面饼图所示。下图可以清楚地看出,北京遥遥领先,占比近37%,广东、上海、浙江和江苏紧随其后。这跟大家对人工智能行业的传统认知也是十分接近的。
4.2 国产大模型城市分布
按城市来看,排在前列的城市地图如下:
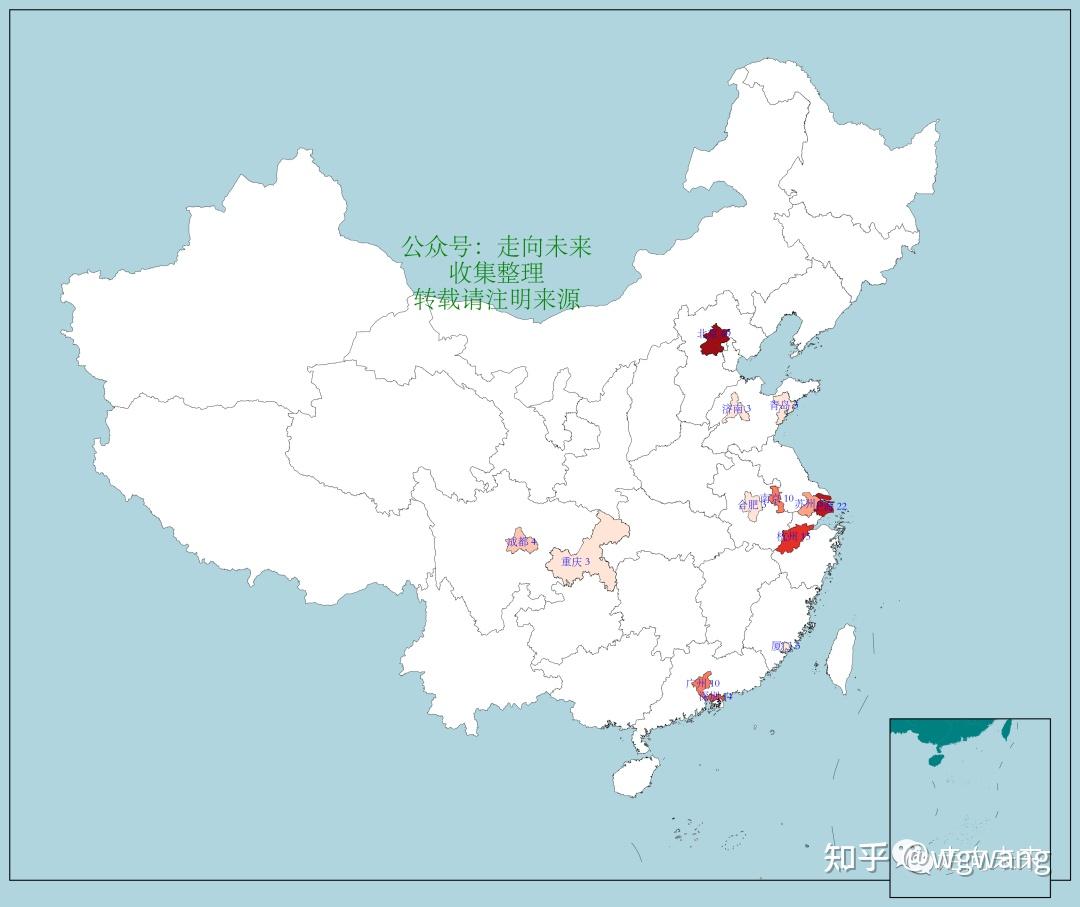
4.3 国产大模型城市五强
具体来说,排名前五的分别是北京、上海、杭州、深圳和广州。这与大家的传统认知是一致和吻合的。过往许多的报告都提到,北京、上海、深圳、杭州和广州是中国最具人工智能发展潜力的五大城市。事实上,这些城市在人工智能核心技术、应用场景、产业生态和政策环境等方面都做的非常好,人工智能大厂也多数坐落于上述五大城市。
| 序号 | 城市 | 数量 |
| 1 | 北京 | 69 |
| 2 | 上海 | 22 |
| 3 | 杭州 | 15 |
| 4 | 深圳 | 14 |
| 5 | 广州 | 10 |
- 北京:北京是中国大模型的领军城市,拥有全国最多的发布了大模型的机构,同时在论文和人才方面也处于领先水平。北京也是大模型有关的人工智能的政策制定和标准制定的中心,并发布了一系列的指导性规划和措施来支持大模型的创新和发展。北京在大模型领域的代表性机构有百度、清华大学、北京智源人工智能研究院、北京大学、中国科学院自动化研究所、中国科学院计算技术研究所、百川智能、云知声、抖音等等。
- 上海:上海是中国大模型的创新高地,也拥有许多的大模型研发机构,同时在投资机构和创业孵化器方面也处于领先水平。上海也是中国人工智能的国际合作和交流的窗口,举办了世界人工智能大会等一系列的国际性活动,展示了中国人工智能的成果和愿景。许多机构选择在WAIC2023上发布了大模型【参考:上海世界人工智能大会WAIC,好看的点都在这里:大模型是绝对的王者,其他呢?】。上海在大模型领域的代表性机构有上海人工智能实验室、复旦大学、上海交通大学、达观数据、商汤科技、稀宇科技等。
- 深圳:深圳是中国人工智能的产业基地,在人工智能相关产业链和配套服务方面名列前茅,特别是与智能硬件有关的产业链,是全球说一不二的地方。同时,深圳也是中国人工智能的创业之都,吸引了大量的优秀的人才和项目,形成了良好的创新氛围和文化。深圳在大模型领域的代表性机构有华为、腾讯、鹏城实验室、香港中文大学深圳校区、IDEA 研究院等等。
- 杭州:杭州是中国人工智能的应用先行者,拥有许许多多人工智能应用场景和案例。杭州也是中国人工智能的示范之城,建立了以城市大脑为核心的智慧城市体系,提升了城市管理和服务水平。杭州在大模型领域的代表性机构有阿里巴巴、浙江大学、之江实验室、蚂蚁集团、恒生电子等等。
- 广州:广州在大模型方面表现也不俗,大模型领域的代表性机构有华南理工大学、云从科技、网易等。
4.4 典型国产大模型评测与点评
参考文章:全面面试国产大模型但不点评,大模型的差距看得见系列之五
4.5 国产大模型榜单
国产大模型榜单如下,请查看 Github 上的 原始数据 “Github :https://github.com/wgwang/LLMs-In-China”
| 序号 | 公司 | 大模型 | 省市 | 类别 | 官网 |
| 1 | 百度 | 文心一言 | 北京 | 通用 | ✔ |
| 2 | 智谱华章 | 清言 | 北京 | 通用 | ✔ |
| 3 | 百川智能 | 百川 | 北京 | 通用 | ✔ |
| 4 | 达观数据 | 曹植 | 上海 | 工业 | ✔ |
| 5 | 上海AI实验室 | 书生 | 上海 | 通用 | ✔ |
| 6 | 科大讯飞 | 星火 | 安徽合肥 | 通用 | ✔ |
| 7 | 深度求索 | Deepseek Coder | 浙江杭州 | 代码 | ✔ |
| 8 | 商汤科技 | 日日新 | 上海 | 通用 | ✔ |
| 9 | 春田知韵(抖音) | 豆包 | 北京 | 通用 | ✔ |
| 10 | 中国科学院自动化研究所 | 紫东·太初 | 北京 | 通用 | ✔ |
| 11 | 阿里云 | 通义千问 | 浙江杭州 | 通用 | ✔ |
| 12 | 华为 | 盘古,盘古气象,盘古-Σ | 广东深圳 | 工业 | ✔ |
| 13 | 复旦大学 | MOSS | 上海 | 科研 | ✔ |
| 14 | 智源AI研究院 | 悟道·天鹰,悟道·EMU | 北京 | 通用 | ✔ |
| 15 | 浙江大学 | 启真,TableGPT,智海-录问,智海-三乐,PromptProtein | 浙江杭州 | 垂直 | ✔ |
| 16 | OpenBMB | CPM,CPM-Bee | 北京 | 通用 | ✔ |
| 17 | 元象科技 | XVERSE-13B | 广东深圳 | 通用 | ✔ |
| 18 | 腾讯 | 混元 | 广东深圳 | 通用 | ✔ |
| 19 | 云知声 | 山海 | 北京 | 医学 | ✔ |
| 20 | 东北大学 | TechGPT,PICA | 辽宁沈阳 | 科研 | ✔ |
| 21 | IDEA研究院 | 封神榜MindBot,ziya-coding | 广东深圳 | 通用 | ✔ |
| 22 | 贝壳 | BELLE | 北京 | 垂直 | ✔ |
| 23 | 360 | 智脑,一见 | 北京 | 通用 | ✔ |
| 24 | 哈尔滨工业大学 | 本草,活字 | 黑龙江哈尔滨 | 医学 | ✔ |
| 25 | 北京大学信息工程学院 | ChatLaw | 北京 | 法律 | ✔ |
| 26 | 港中文深圳 | 华佗,凤凰 | 广东深圳 | 医学 | ✔ |
| 27 | 中国科学院计算技术研究所 | 百聆 | 北京 | 科研 | ✔ |
| 28 | 好未来 | MathGPT | 北京 | 教育 | ✔ |
| 29 | 晓多科技+国家超算成都中心 | 晓模型XPT | 四川成都 | 客服 | ✔ |
| 30 | 昆仑万维 | 天工Skywork | 北京 | 通用 | ✔ |
| 31 | 中国科学院成都计算机应用研究所 | 聚宝盆 | 四川成都 | 金融 | ✔ |
| 32 | 华南理工大学 | 扁鹊,灵心SoulChat | 广东广州 | 医学 | ✔ |
| 33 | 虎博科技 | TigerBot | 上海 | 金融 | ✔ |
| 34 | 度小满 | 轩辕 | 北京 | 金融 | ✔ |
| 35 | 北京交通大学 | 致远 | 北京 | 交通 | ✔ |
| 36 | 恒生电子 | LightGPT | 浙江杭州 | 金融 | ✘ |
| 37 | 上海交通大学 | K2,白玉兰 | 上海 | 科学 | ✔ |
| 38 | 左手医生 | 左医GPT | 北京 | 医学 | ✔ |
| 39 | 上海科技大学 | DoctorGLM | 上海 | 医学 | ✔ |
| 40 | 华东师范大学 | EmoGPT,EduChat | 上海 | 教育 | ✘ |
| 41 | 艾写科技 | Anima | 浙江杭州 | 营销 | ✔ |
| 42 | 澳门理工大学 | XrayGLM,IvyGPT | 澳门 | 医疗 | ✔ |
| 43 | 北京语言大学 | 桃李 | 北京 | 教育 | ✔ |
| 44 | 中工互联 | 智工 | 北京 | 工业 | ✘ |
| 45 | 稀宇科技 | ABAB | 上海 | 通用 | ✔ |
| 46 | 追一科技 | 博文Bowen | 广东深圳 | 客服 | ✘ |
| 47 | 智慧眼 | 砭石 | 湖南长沙 | 医学 | ✘ |
| 48 | 香港科技大学 | 罗宾Robin | 香港 | 科研 | ✔ |
| 49 | 网易有道 | 子曰 | 北京 | 教育 | ✔ |
| 50 | 智媒开源研究院 | 智媒 | 广东深圳 | 媒体 | ✔ |
| 51 | 创业黑马 | 天启 | 北京 | 创投 | ✘ |
| 52 | 蚂蚁集团 | 贞仪,CodeFuse | 浙江杭州 | 金融 | ✔ |
| 53 | 硅基智能 | 炎帝 | 江苏南京 | 文旅 | ✘ |
| 54 | 西湖心辰 | 西湖 | 浙江杭州 | 科研 | ✔ |
| 55 | 国家超级计算天津中心 | 天河天元 | 天津 | 通用 | ✘ |
| 56 | 星环科技 | 无涯、求索 | 上海 | 金融 | ✘ |
| 57 | 清博智能 | 先问 | 北京 | 农业 | ✘ |
| 58 | 智子引擎 | 元乘象 | 江苏南京 | 客服 | ✔ |
| 59 | 拓世科技 | 拓世 | 江西南昌 | 金融 | ✘ |
| 60 | 医疗算网 | Uni-talk | 上海 | 医学 | ✘ |
| 61 | 慧言科技+天津大学 | 海河·谛听 | 天津 | 科研 | ✘ |
| 62 | 第四范式 | 式说 | 北京 | 客服 | ✔ |
| 63 | 拓尔思 | 拓天 | 北京 | 媒体 | ✘ |
| 64 | 出门问问 | 序列猴子 | 北京 | 营销 | ✔ |
| 65 | 数说故事 | SocialGPT | 广东广州 | 社交 | ✘ |
| 66 | 云从科技 | 从容 | 广东广州 | 政务 | ✔ |
| 67 | 浪潮信息 | 源 | 山东济南 | 通用 | ✘ |
| 68 | 中国农业银行 | 小数ChatABC | 北京 | 金融 | ✘ |
| 69 | 麒麟合盛 | 天燕AiLMe | 北京 | 运维 | ✔ |
| 70 | 台智云 | 福尔摩斯FFM | 台湾 | 工业 | ✔ |
| 71 | 医联科技 | medGPT | 四川成都 | 医学 | ✘ |
| 72 | 电信智科 | 星河 | 北京 | 通信 | ✘ |
| 73 | 深思考人工智能 | Dongni | 北京 | 媒体 | ✔ |
| 74 | 文因互联 | 文因 | 安徽合肥 | 金融 | ✘ |
| 75 | 印象笔记 | 大象GPT | 北京 | 媒体 | ✘ |
| 76 | 中科闻歌 | 雅意 | 北京 | 媒体 | ✘ |
| 77 | 澜舟科技 | 孟子 | 北京 | 金融 | ✔ |
| 78 | 京东 | 言犀 | 北京 | 商业 | ✘ |
| 79 | 香港中文大学 | PointLLM | 香港 | 通用 | ✔ |
| 80 | 清华大学 | NowcastNet | 北京 | 科研 | ✔ |
| 81 | 鹏城实验室 | 鹏城·脑海 | 广东深圳 | 科研 | ✘ |
| 82 | 宇视科技 | 梧桐 | 浙江杭州 | 运维 | ✘ |
| 83 | 智臻智能 | 华藏 | 上海 | 客服 | ✘ |
| 84 | 美亚柏科 | 天擎 | 福建厦门 | 安全 | ✘ |
| 85 | 山东大学 | 夫子•明察 | 山东济南 | 司法 | ✔ |
| 86 | 数慧时空 | 长城 | 北京 | 地球科学 | ✘ |
| 87 | 循环智能 | 盘古 | 北京 | 客服 | ✔ |
| 88 | 知乎 | 知海图 | 北京 | 媒体 | ✘ |
| 89 | 网易伏羲 | 玉言 | 广东广州 | 通用 | ✘ |
| 90 | 清睿智能 | ArynGPT | 江苏苏州 | 教育 | ✘ |
| 91 | 微盟 | WAI | 上海 | 商业 | ✔ |
| 92 | 西北工业大学+华为 | 秦岭·翱翔 | 陕西西安 | 工业 | ✘ |
| 93 | 奇点智源 | 天工智力 | 北京 | 通用 | ✔ |
| 94 | 联汇科技 | 欧姆 | 浙江杭州 | 通用 | ✔ |
| 95 | 中国联通 | 鸿湖 | 北京 | 通信 | ✘ |
| 96 | 思必驰 | DFM-2 | 江苏苏州 | 工业 | ✘ |
| 97 | 中国科学院计算机网络信息中心 | MatChat | 北京 | 材料 | ✔ |
| 98 | 电科太极 | 小可 | 北京 | 政务 | ✘ |
| 99 | 中国移动 | 九天,九天•众擎 | 北京 | 通信 | ✘ |
| 100 | 中国电信 | TeleChat,启明 | 北京 | 通信 | ✘ |
| 101 | 容联云 | 赤兔 | 北京 | 客服 | ✘ |
| 102 | 理想科技 | 大道Dao | 北京 | 运维 | ✘ |
| 103 | 乐言科技 | 乐言 | 上海 | 客服 | ✘ |
| 104 | 沪渝AI研究院 | 兆言 | 重庆 | 科研 | ✘ |
| 105 | 中央广播电视总台 | 央视听 | 北京 | 媒体 | ✘ |
| 106 | 超对称技术公司 | 乾元 | 北京 | 金融 | ✔ |
| 107 | 蜜度 | 文修 | 上海 | 媒体 | ✘ |
| 108 | 中国电子云 | 星智 | 湖北武汉 | 政务 | ✘ |
| 109 | 理想汽车 | MindGPT | 北京 | 工业 | ✘ |
| 110 | 阅文集团 | 妙笔 | 上海 | 文旅 | ✘ |
| 111 | 携程 | 问道 | 上海 | 文旅 | ✘ |
| 112 | 实在智能 | 塔斯 | 浙江杭州 | 客服 | ✘ |
| 113 | 瑞泊 | VIDYA | 北京 | 工业 | ✔ |
| 114 | 有连云 | 麒麟 | 上海 | 金融 | ✘ |
| 115 | 维智科技 | CityGPT | 上海 | 公共服务 | ✘ |
| 116 | 用友 | YonGPT | 北京 | 企业服务 | ✘ |
| 117 | 天云数据 | Elpis | 北京 | 金融 | ✘ |
| 118 | 孩子王 | KidsGPT | 江苏南京 | 教育 | ✘ |
| 119 | 佳都科技 | 佳都知行 | 广东广州 | 交通 | ✘ |
| 120 | 今立方 | 12333 | 福建厦门 | 政务 | ✘ |
| 121 | 阳光保险集团 | 正言 | 广东深圳 | 金融 | ✘ |
| 122 | 中科创达 | 魔方Rubik | 北京 | 工业 | ✘ |
| 123 | 聆心智能 | CharacterGLM | 北京 | 游戏 | ✘ |
| 124 | 大经中医 | 岐黄问道 | 江苏南京 | 医疗 | ✘ |
| 125 | 蒙牛 | MENGNIU.GPT | 内蒙古呼和浩特 | 食品 | ✘ |
| 126 | 快商通 | 汉朝 | 福建厦门 | 营销 | ✘ |
| 127 | 众合科技 | UniChat | 浙江杭州 | 交通 | ✘ |
| 128 | 金蝶 | 苍穹 | 广东深圳 | 企业服务 | ✘ |
| 129 | 云问科技 | 云中问道 | 江苏南京 | 营销 | ✘ |
| 130 | 天壤智能 | 小白 | 上海 | 通用 | ✘ |
| 131 | 小米 | MiLM-6B | 北京 | 商业 | ✘ |
| 132 | 长虹 | 长虹超脑 | 四川绵阳 | 媒体 | ✘ |
| 133 | 开普云 | 开悟 | 广东东莞 | 政务 | ✔ |
| 134 | 赛灵力科技 | 达尔文 | 广东广州 | 医学 | ✘ |
| 135 | 航旅纵横 | 千穰大模型 | 北京 | 民航 | ✘ |
| 136 | 奇安信 | Q-GPT | 北京 | 信息安全 | ✘ |
| 137 | 车之谷 | 叆谷 | 山东青岛 | 汽车 | ✘ |
| 138 | 索贝时代 | 明眸 | 四川成都 | 媒体 | ✘ |
| 139 | 海尔 | HomeGPT | 山东青岛 | 智能家居 | ✘ |
| 140 | 马上消费 | 天镜 | 重庆 | 金融 | ✘ |
| 141 | 白海科技 | 白聚易 | 北京 | 营销 | ✘ |
| 142 | 二元工业 | 妆舟 | 江苏苏州 | 日化 | ✘ |
| 143 | 格创东智 | 章鱼智脑 | 广东广州 | 工业制造 | ✘ |
| 144 | 创业邦 | BangChat | 北京 | 创投 | ✘ |
| 145 | 新华三H3C | 百业灵犀 | 浙江杭州 | 工业 | ✘ |
| 146 | 作业帮 | 银河 | 广东广州 | 教育 | ✘ |
| 147 | 企查查 | 知彼阿尔法 | 江苏苏州 | 商业 | ✘ |
| 148 | 绿盟 | 风云卫 | 北京 | 网络安全 | ✘ |
| 149 | 江苏欧软 | WISE | 江苏苏州 | 工业 | ✘ |
| 150 | 创新奇智 | 奇智孔明 | 山东青岛 | 工业 | ✘ |
| 151 | 大汉软件 | 星汉 | 江苏南京 | 政务 | ✘ |
| 152 | 零点有数 | 零点楷模 | 北京 | 政务 | ✘ |
| 153 | 国农生猪大数据中心 | PIGGPT | 重庆 | 农业 | ✘ |
| 154 | 微脉 | CareGPT | 浙江杭州 | 医疗 | ✘ |
| 155 | 吉大正元 | 昆仑 | 吉林长春 | 信息安全 | ✘ |
| 156 | 武汉大学 | CheeseChat | 湖北武汉 | 教育 | ✘ |
| 157 | 方正电子 | 魔方 | 北京 | 媒体 | ✘ |
| 158 | 似然实验室 | TraderGPT | 广东广州 | 金融 | ✘ |
| 159 | 网易智企 | 商河 | 广东广州 | 客服 | ✘ |
| 160 | 深圳供电局 | 祝融2.0 | 广东深圳 | 电力 | ✘ |
| 161 | 万兴科技 | 天幕 | 西藏拉萨 | 媒体 | ✘ |
| 162 | 惟远智能 | 千机百智 | 广东深圳 | 客服 | ✘ |
| 163 | 兔展智能 | 兔灵 | 广东深圳 | 营销 | ✘ |
| 164 | 中国科学技术大学 | UniDoc | 安徽合肥 | 通用 | ✘ |
| 165 | 钢谷网 | 谷蚁 | 陕西西安 | 电商 | ✘ |
| 166 | 浪潮海岳 | inGPT | 山东济南 | 企业服务 | ✘ |
| 167 | 木卫四科技 | 蝴蝶 | 北京 | 汽车 | ✘ |
| 168 | 汇通达网络 | 汇通达 | 江苏南京 | 企业服务 | ✘ |
| 169 | 九章云极 | 元识 | 北京 | 企业服务 | ✘ |
| 170 | 汉王 | 天地 | 北京 | 法律 | ✘ |
| 171 | 南京审计大学 | 审元 | 江苏南京 | 审计 | ✘ |
| 172 | 天翼云 | 慧泽 | 北京 | 政务 | ✘ |
| 173 | 北京大学行为与空间智能实验室 | PlanGPT | 北京 | 城市规划 | ✘ |
| 174 | 吉林大学 | 棱镜 | 吉林长春 | 通用 | ✘ |
| 175 | 慧安股份 | 蜂巢知元 | 北京 | 工业 | ✘ |
| 176 | VIVO | 蓝心 | 广东东莞 | 消费电子 | ✘ |
| 177 | 元年科技 | 方舟GPT | 北京 | 企业服务 | ✘ |
| 178 | 电科数字 | 智弈 | 上海 | 水利 | ✘ |
| 179 | 云天励飞 | 天书 | 广东深圳 | 政务 | ✘ |
| 180 | 北京理工大学东南信息技术研究院 | 明德 | 福建莆田 | 通用 | ✘ |
| 181 | 恩博科技 | 林海思绪 | 江苏南京 | 林业 | ✘ |
| 182 | 亿嘉和 | YJH-LM | 江苏南京 | 消费电子 | ✘ |
| 183 | 大华股份 | 星汉 | 浙江杭州 | 城市治理 | ✘ |
| 184 | 福建医科大学孟超肝胆医院 | 孟超 | 福建福州 | 医疗 | ✘ |
| 185 | 中文在线 | 中文逍遥 | 北京 | 文旅 | ✘ |
| 186 | CCAI宁波中心 | iChainGPT | 浙江宁波 | 企业服务 | ✘ |
| 187 | 光启慧语 | 光语 | 上海 | 医疗 | ✘ |
| 188 | 安恒信息 | 恒脑 | 浙江杭州 | 信息安全 | ✘ |

第五章 大模型典型应用
暂缺,敬请期待。
最后,对通用人工智能有兴趣的,推荐阅读下面文章:
语义增强可编程知识图谱框架SPG白皮书在 CCKS2023发布,为知识图谱赋能AGI 夯实基础(附白皮书下载链接)
珠峰书《知识图谱:认知智能理论与实战》“升级”了:配套PPT,教学更easy!
如果觉得文章对你有用,请随手打赏。你的赞赏,是两个孩子的爸爸努力码字的最强大的动力!