为什么说Intel的大小核调度不好呢?
都说大小核在重度任务时可能会调用到小核,导致性能发挥不佳,但是在此之前早都有超线程技术了,重度任务也可能调度到超线程上,已知超线程虚拟核心的性能仅为物理核心的2...

- 3 个点赞 👍
我现在就在这下战书[尴尬]不喜欢大小核的欢迎来跟我对线:
问题1:你认为大小核缺的是性能还是调度?
问题2:你认为调度问题是应该由谁来负责?Intel内置的调度器,win系统,还是自己动手process lasso?
问题3:如何Intel+win的调度你认为不合理,你会怎么做?A躺平然后火力全开直接骂 B自己动手process lasso调度
问题4:你认为什么软件应该运行在小核上?
问题5:你认为小核的性能是什么水平?
问题6:调度小核,然后卡顿的原因是什么?
查看全文>>
GiantStructure - 75 个点赞 👍
超线程和小核不是一回事,调度简单多了。
超线程并不存在主核副核之分,同一物理核心上的两个逻辑核心是相同的。之所以超线程的两个线程性能加起来只相当于单核心的125~160%,是因为超线程的原理在于尽可能降低CPU执行单元的闲置时间。
CPU单个核心有多种运算单元,部分运算单元还有多个相同的,虽然现代CPU有多种机制如乱序执行、寄存器重命名等尽可能在一个时钟周期内执行多条指令,但也无法保证这些执行单元每个时钟周期都在满负荷工作。至于因为分支预测失败、内存访问等待期间的流水线空泡,也是只能尽量降低但无法完全避免的,空泡出现时,所有执行单元都在闲置。此外应用程序本身也可能导致部分执行单元闲置——例如普通整数应用几乎用不到浮点单元,执行这类应用的线程时浮点单元几乎一直闲置。
超线程的原理就是利用第二个线程的指令来利用上这些闲置的执行单元。可以说,超线程效率越高,意味着单线程时CPU的浪费越严重。压缩软件因为存在大量的比对-判断,相比其他应用的分支预测失败率和缓存命中失败率都更高,所以超线程效率比一般应用要高。
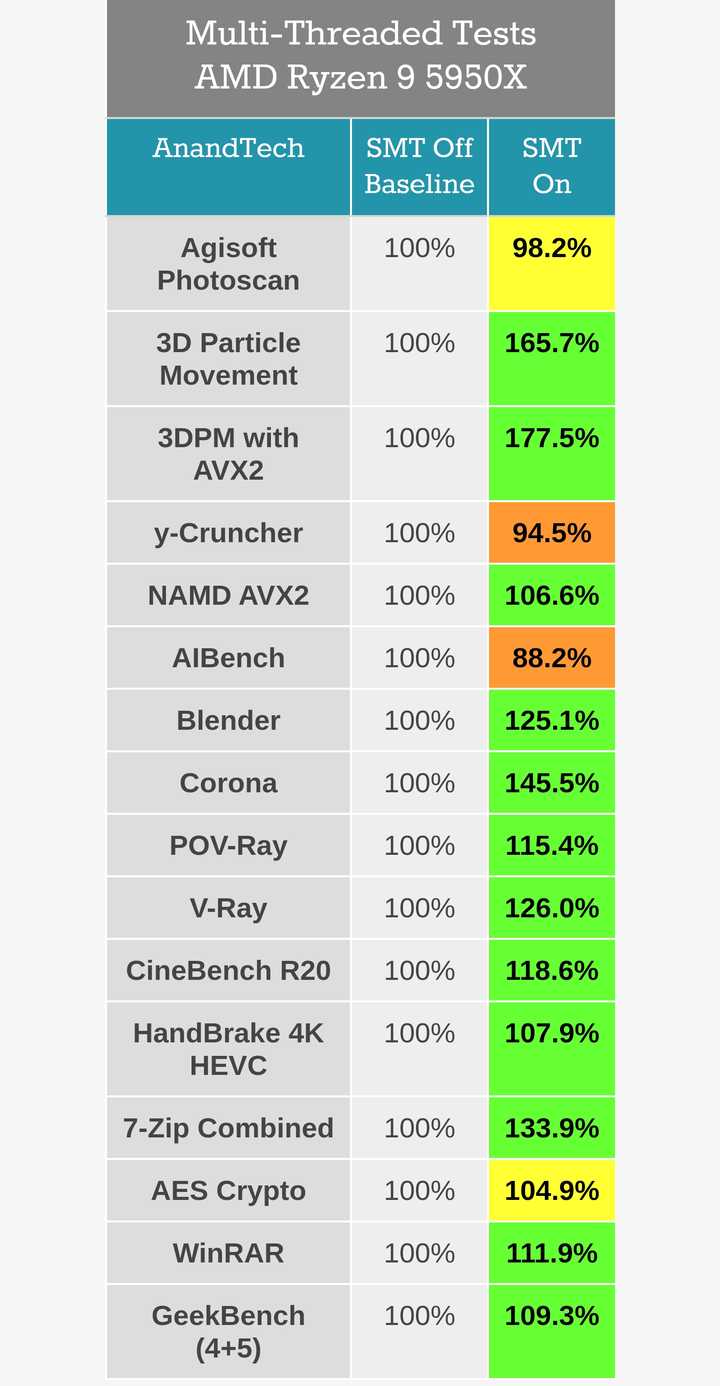

PS:超线程因为两个线程之间都在一个物理核心上执行,线程之间交互延迟很低。如果多个线程之间交互很频繁的话也能大幅提升性能,例如上面计算粒子3D碰撞的3DPM,开启超线程后性能超过了160%,开启AVX支持是甚至超过170%。
反过来某些本来就执行效率就很高的应用,启用超线程后两个线程之间还要争抢执行单元,性能可能反而有所降低,例如上面的Y-Cruncher、AI-Benchmark,都是AVX优化应用而且数据量足够大,执行单元很少闲置,所以开启超线程后甚至性能明显降低。
所以操作系统对于超线程的调度很简单:A核心上有线程在执行,而且还有其它核心空闲,那就用其它核心执行新的线程而不要分配到A核心上。
大小核的调度,最麻烦的是操作系统不知道你怎么想。一个渲染应用被你放到后台了,你是希望留出全部大核跑游戏呢还是就留两个大核给你水群刷知乎就够?甚至你一开始只是想刷知乎水个群,结果群里哥们拉你开黑…你自己都不知道,操作系统怎么可能猜得准?
然而吐槽大小核调度的人忽略的一个问题是:不是大小核的CPU,当然没有调度问题,因为他根本没有的选择——后台渲染着还想开黑,还想上网水群不卡?
发布于 2022-12-05 08:34・IP 属地广东查看全文>>
木头龙 - 37 个点赞 👍
经过评论区大神 的指点,我特意做多了几次实验,重复了几次,发现很多不同的地方。
结论是:以下的情况不算是大小核调度问题。调度的优先级是:大核>小核>超线程。
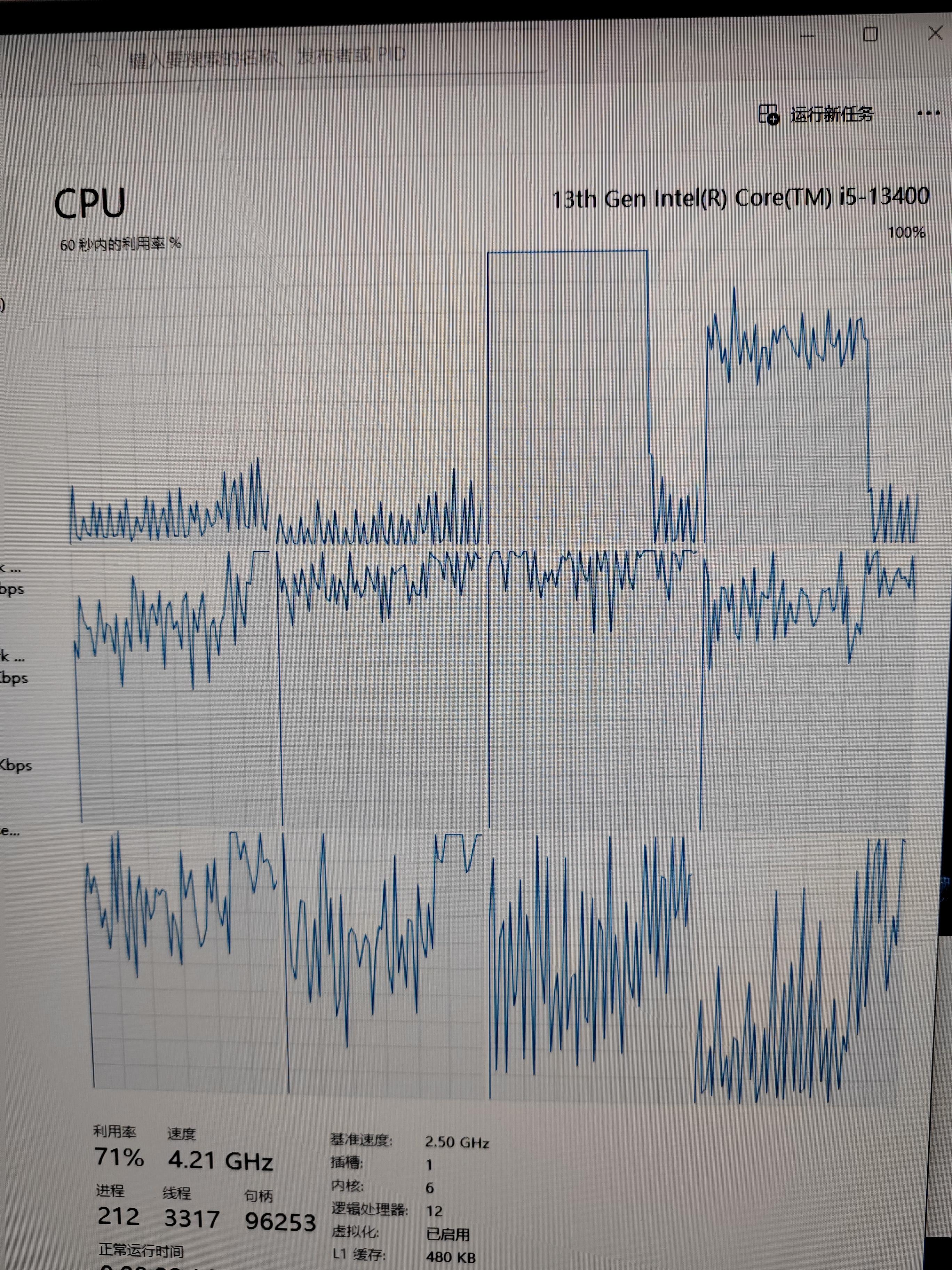
本文的例子出现的是十核单线程运行,存在大小核调度问题的可能;屏蔽小核后,出现五核双线程运行,交替一核休息的情况。即不需要12个线程满负荷运行。
即十核单线程就是最优调度。
序号 名称 CPU 调整 运行时间 情况 解释 1 第一次实验 Intel 十核全开 1h20min 十核单线程运行 偏离值 2 实验一 Intel 关闭四个小核 58min 5核10线程满载运行,存在轮流休息的一个核心 3 实验二 Intel 重新开启四个小核 58min 十核单线程运行 4 重复实验二 Intel 玩20分钟穿越火线后再测 58min 4个小核先休息了6分钟 5 实验三 Intel 分别关闭1、2、3个小核测试 待定 6 实验四 AMD 核心全开 待定 7 8 9 同时,我也注意到 样本量过少 和 为了节省时间只选取 前面十分钟 的部分消耗进行监控,存在差异和误差也不奇怪。
实验待改进的点是:
1.还需要使用AMD全大核双线程CPU跑一次程序。
2.分别关闭1、2、3个小核,重新运行实验,看是否会得到类似结论。
测试配置如下:
组件 型号 CPU i5-13400(10核16线程,6大核4小核) GPU RTX 3060 12GB 内存 2*32GB DDR4 3200频率 硬盘 PCIE 3.0 电源 650W 主板 铭瑄B760M终结者D4 系统 win11 22H2 测试标准
测试软件 测试软件 算法 SVFI 4.0 对4k60帧视频进行超分辨率处理 realESR
实验一:关闭小核,全用大核跑 SVFI 4.0
实验二:实验一之后,重新开启小核跑程序
先说结论:
1.重复实验发现,两次实验程序运行都需要58分钟,比原回答的第一次实验快了20分钟。没有明显的提升。
2.显存占用上,只用一半的占用,即6G左右。
3.纯大核运行情况下,6个核心中从第一个核心开始降频休息,然后工作;就轮到第二个核心休息。
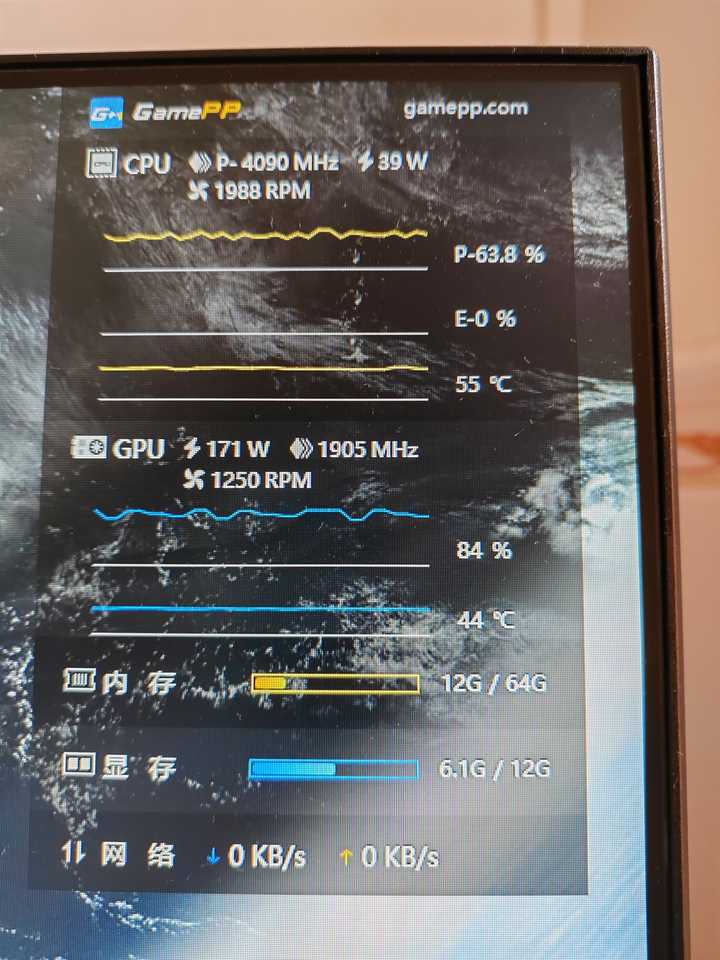
实验一:关闭小核,全用大核跑 SVFI 4.0
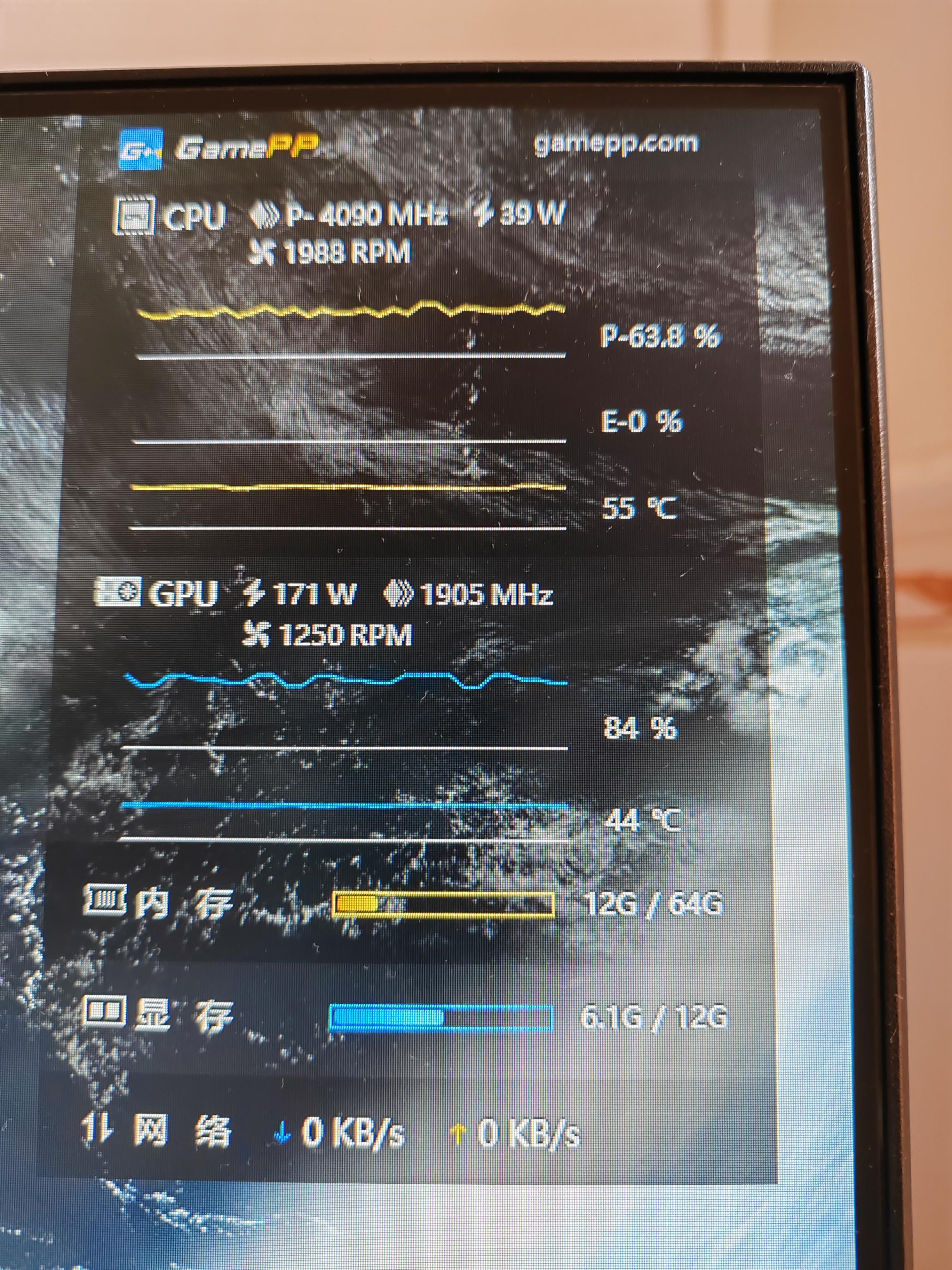
运行过程中,总是存在一颗核心(6个核心中的某一颗)在休息,但确实是可以做到每个核心双线程运行,CPU总占有率在85%左右。运行时间是58分钟。

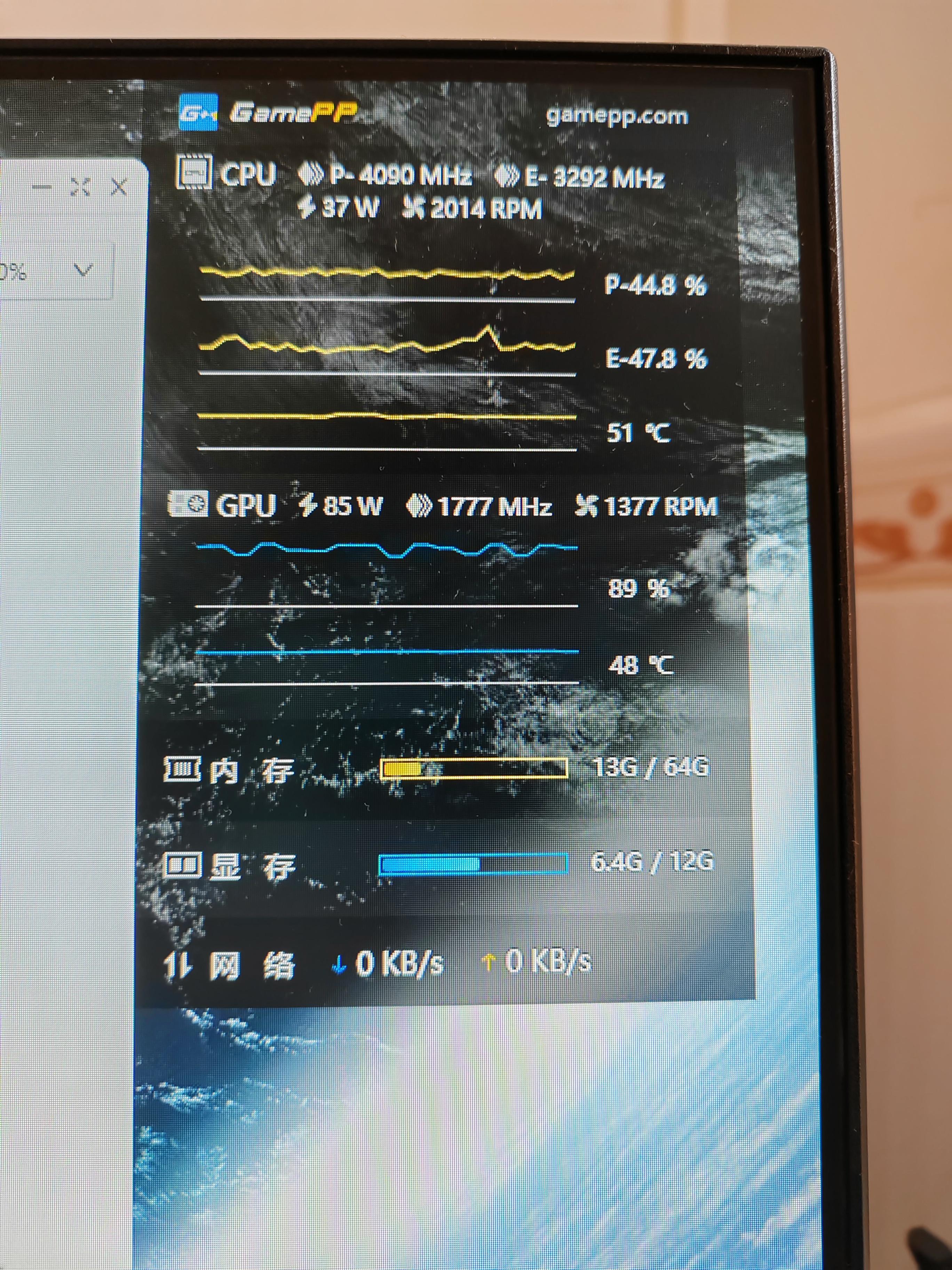
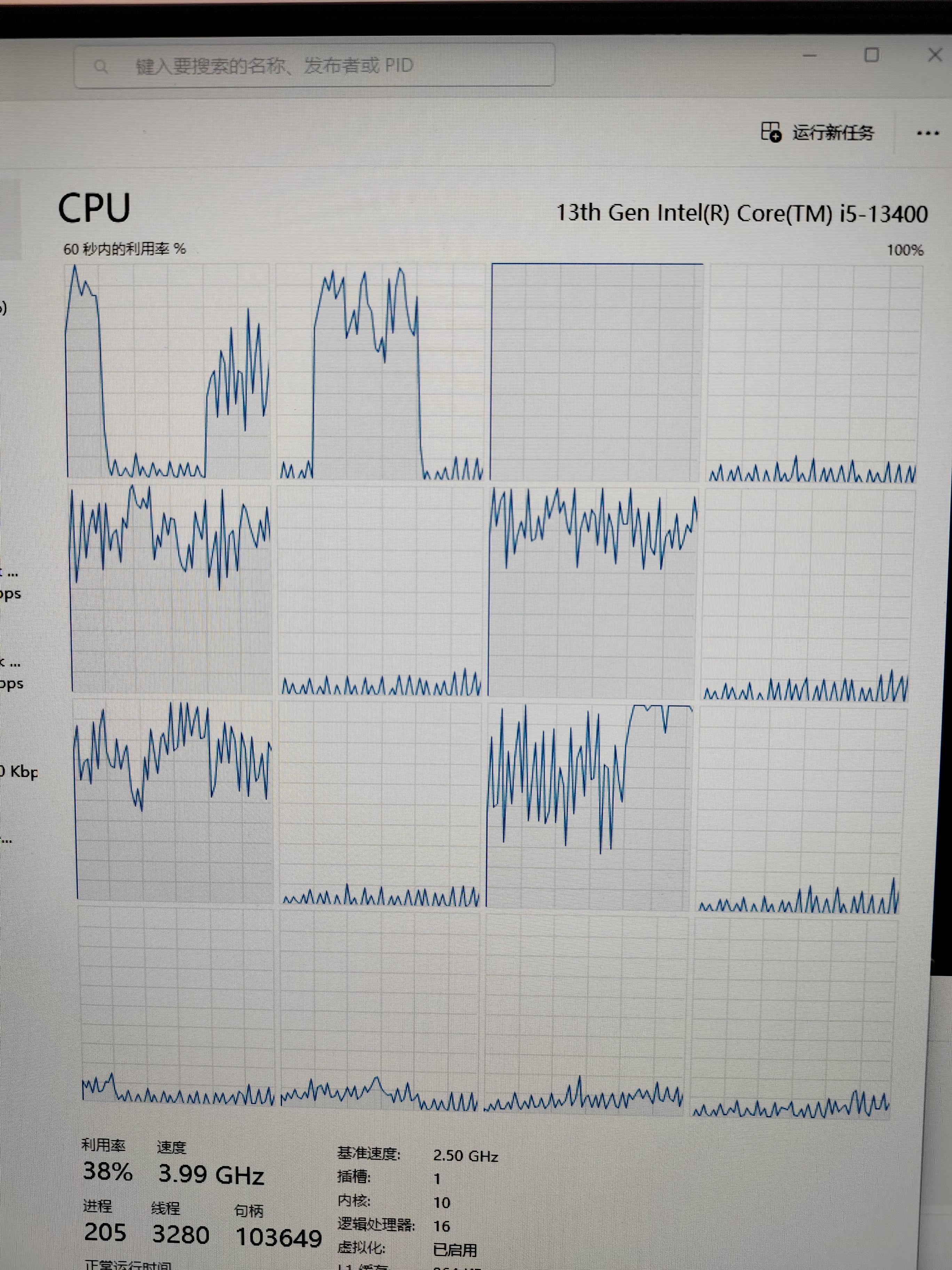
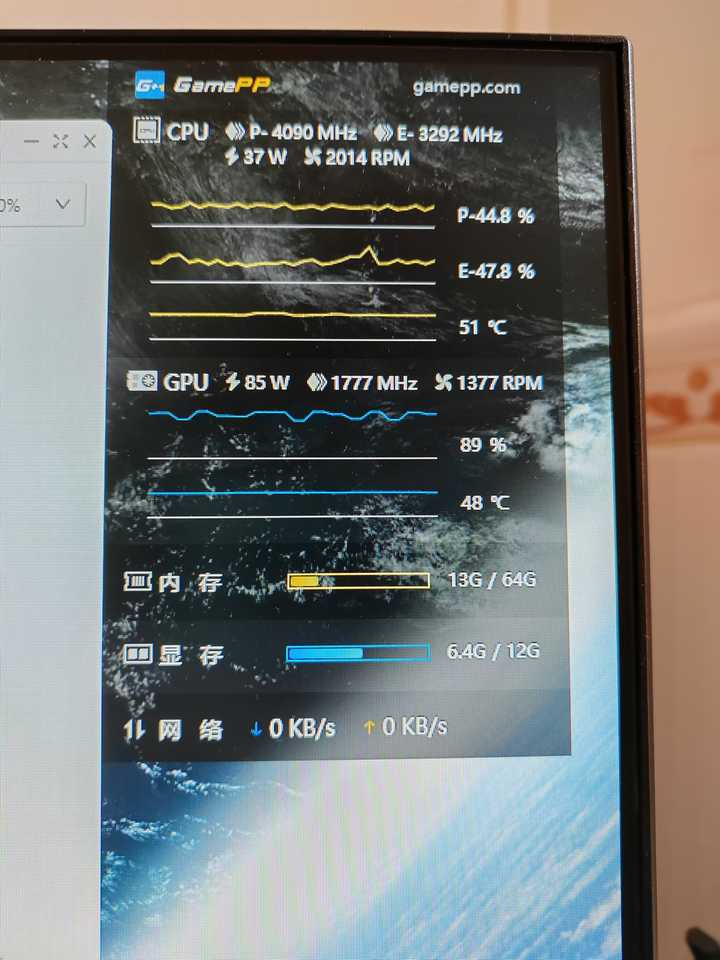
实验二:开启小核重复实验
CPU总体占用率不高,运行需要的时间也是58分钟。
重复实验二:
小核先休息了6分钟,一点也不动。
这是样本量较少导致的偏差。
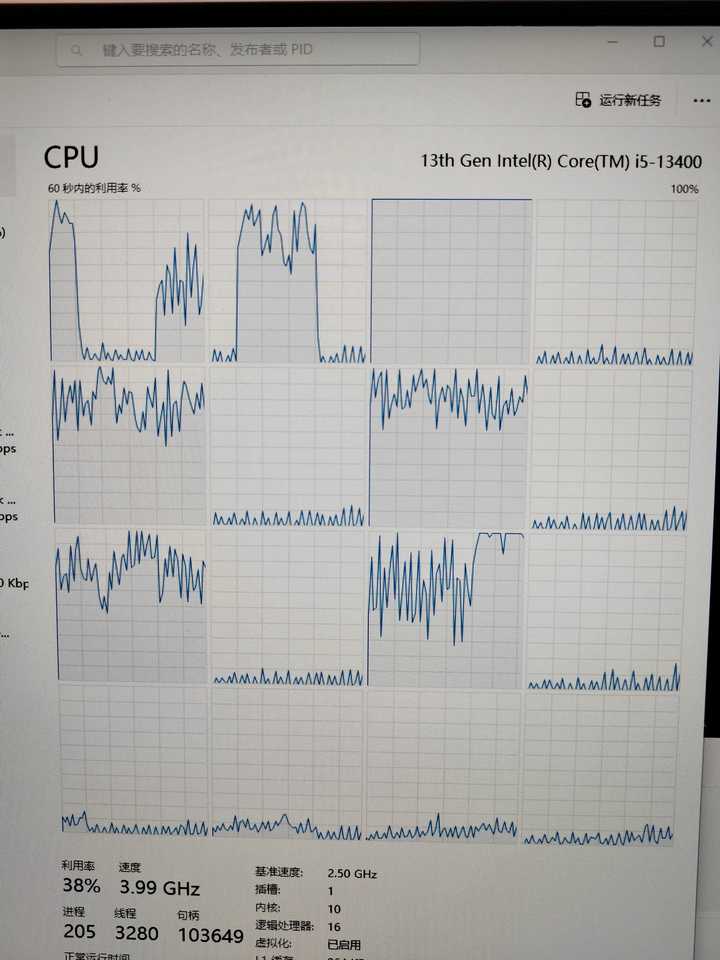
以下是原回答:
时间是,2023年05月14日,距离intel大小核发布已经快两年了。
系统是最新的 win 11 22H2,CPU是i5-13400(6大核 双线程 4小核 单线程,6*2+4*1=16线程),GPU是RTX 3060。
昨天在用SVFI进行4k视频超分,运行需要一个小时二十分钟。
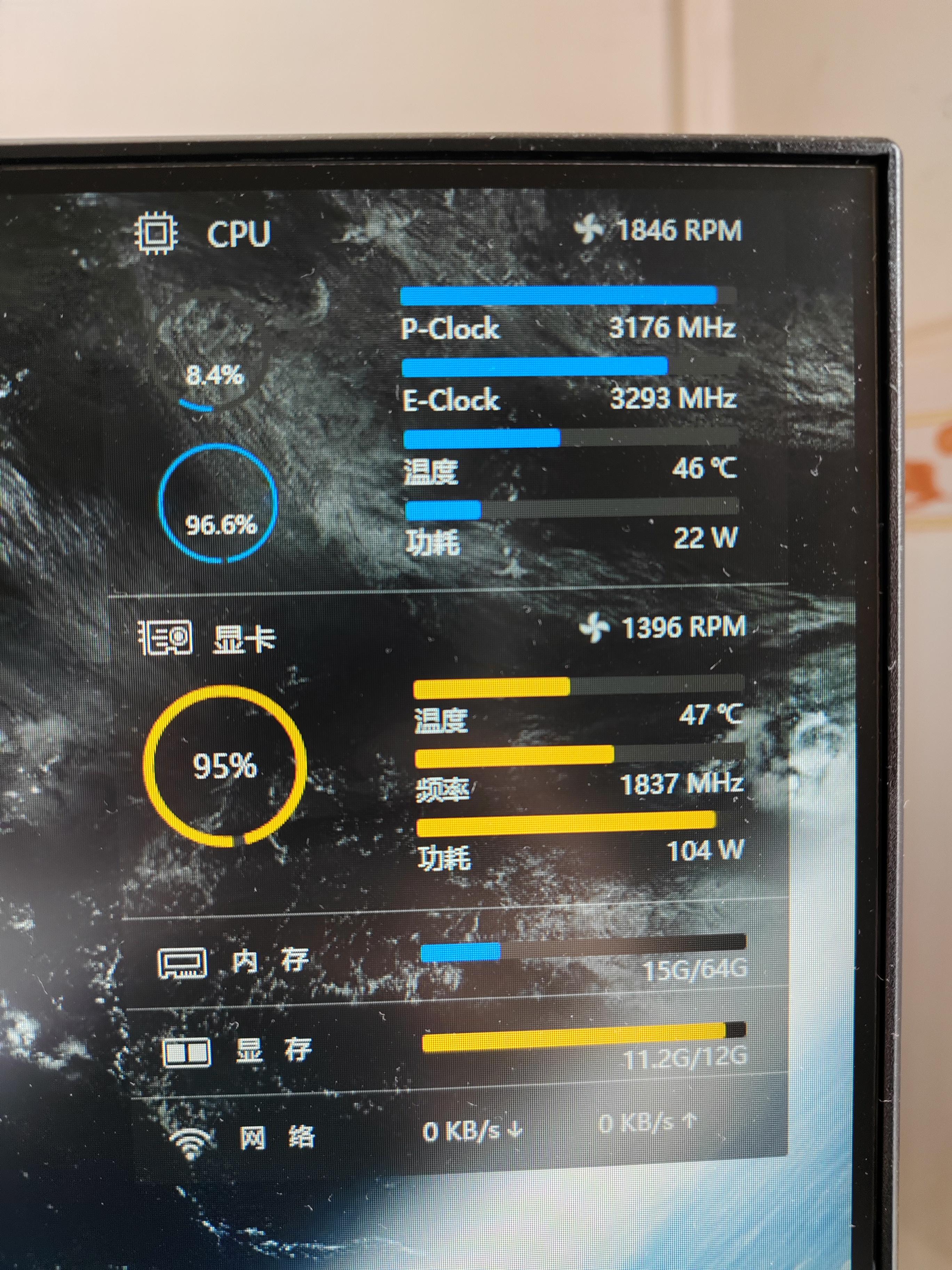
出现神奇现象,小核跑满,大核不动。
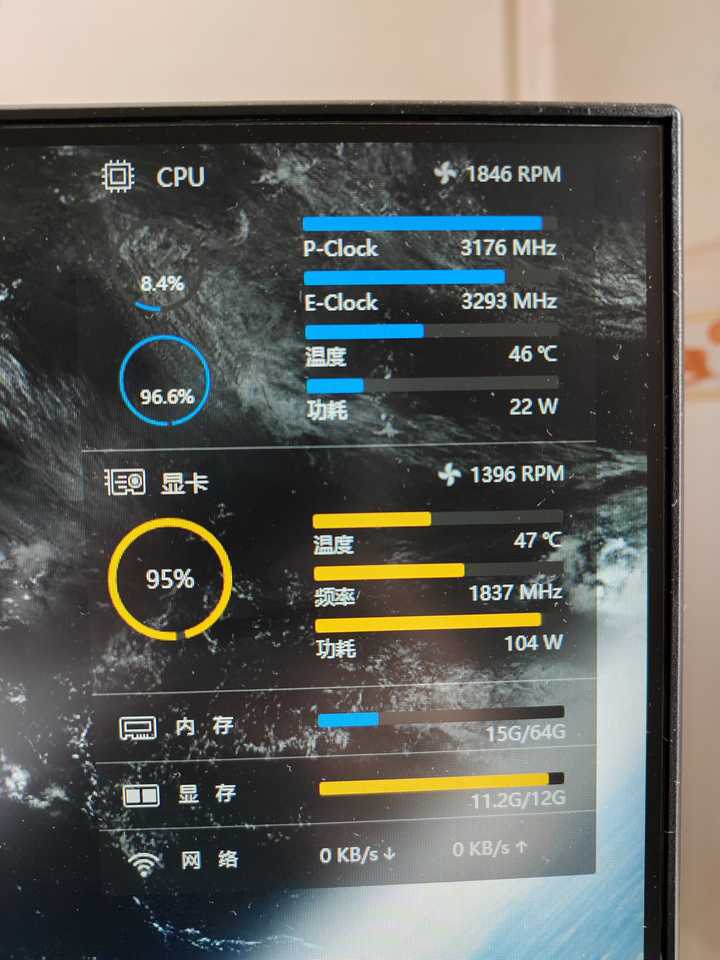
小核跑满线程,大核双线程只能用单线程
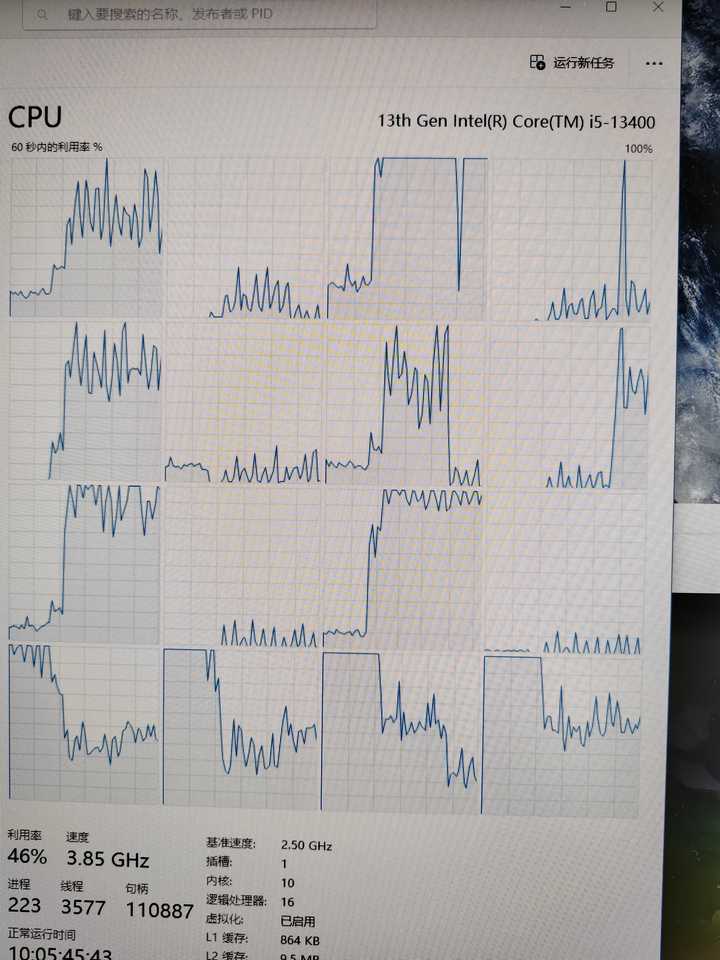
都2023年了,还有大小核调度问题 。。。。。。
编辑于 2023-05-15 21:26・IP 属地广东查看全文>>
Kite - 17 个点赞 👍
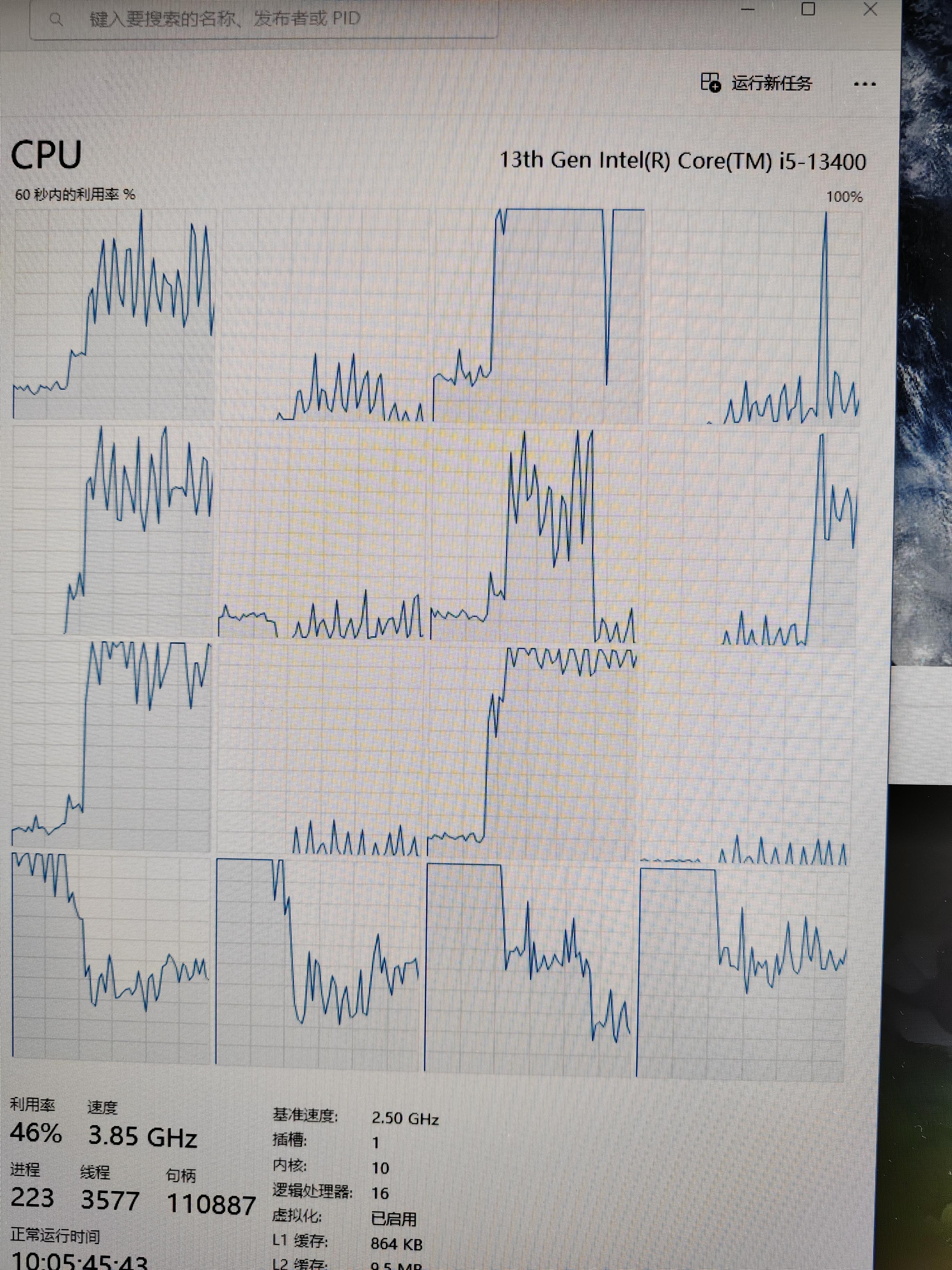
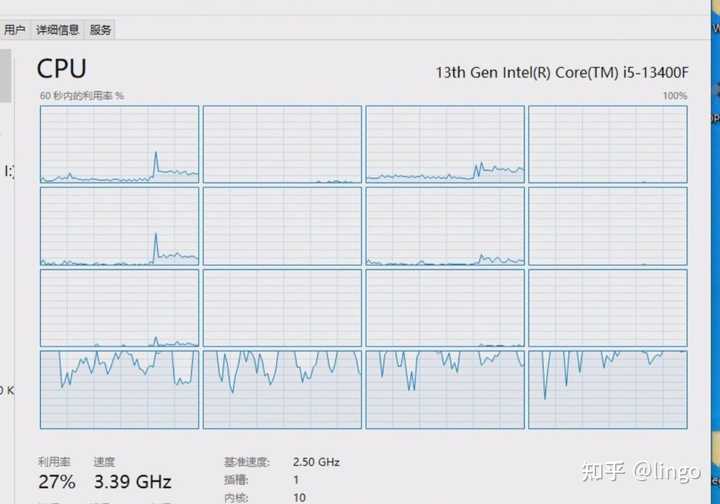
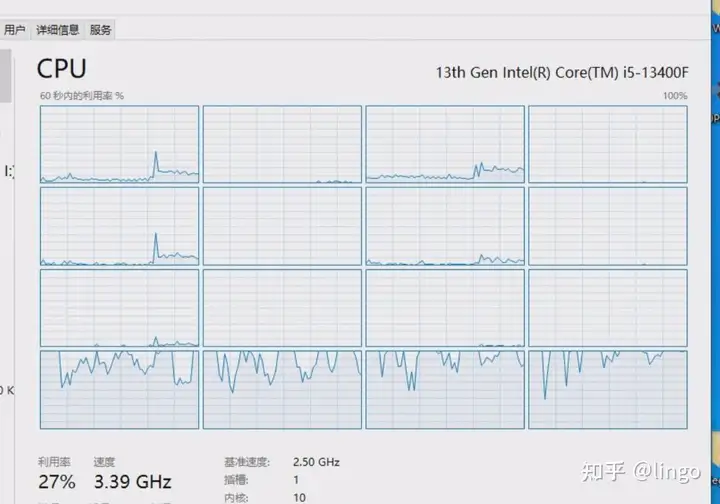
我这u就四个小核,我的编译都跑到四个小核上了。
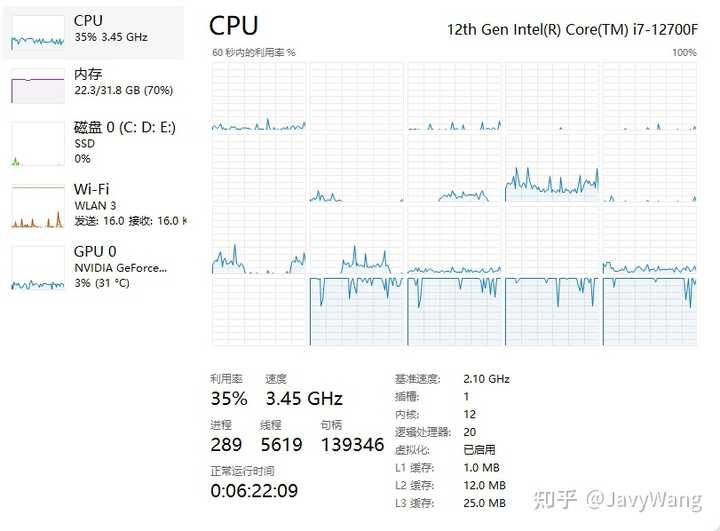
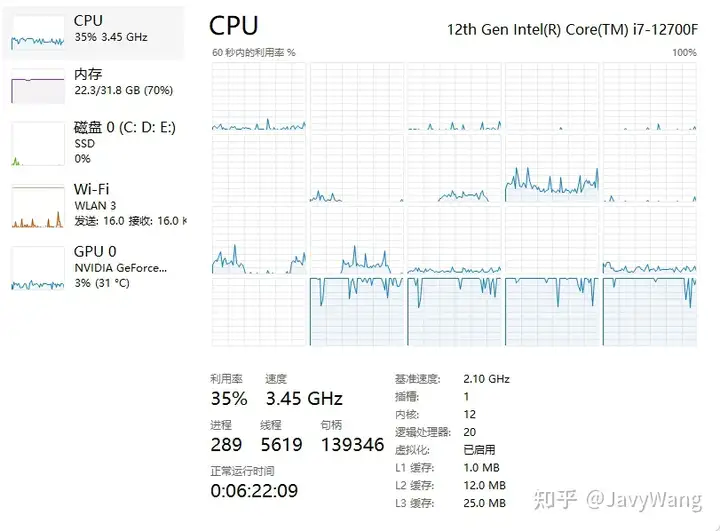
回复一下,还真的不是编译线程数量问题,以下是正常情况,编译配置都一样的。可以看到核心利用得比较均匀
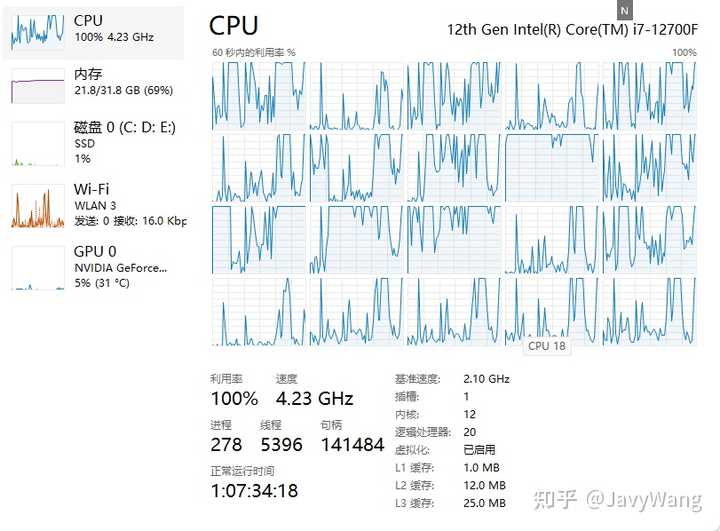
 编辑于 2024-02-01 16:38・IP 属地广东
编辑于 2024-02-01 16:38・IP 属地广东查看全文>>
JavyWang - 8 个点赞 👍
查看全文>>
lingo - 2 个点赞 👍
查看全文>>
karlestira