
想起了电影《我不是药神》。
治疗白血病的专利药“格列卫”4万一盒,一年下来需要十几万,穷人买不起专利药,只能买印度的仿制药。

感觉电影里把矛盾都引向了医药公司,他们面对穷病人的需求毫不动摇,坚持“打假”,看电影的时候气得人脑壳疼。
但是药企和其它行业有很大不同,科研方面的投入相当巨大。药物原材料、人才投入、器材投入,每一样都要花钱,即使这样也不一定能够成功研发出药物。
药界有个著名的“双十”定律:研发一款新药需要10亿美金、10年时间。
《我不是药神》中格列卫的研发公司用了10年,花费了20亿美金才研发出这一药物。只有高价售出,才能逐步收回成本。
这部电影是由真实事件改编的,而“双十”定律也是真实存在的。
AlphaFold2,是DeepMind公司的一个人工智能程序。
2020年11月,AlphaFold2成功地预测出蛋白质的三维结构,在今年预测了98.5%的人类蛋白质,并将这些数据开源。许多科学家和生物医药公司的研究员都很兴奋,表示这将加速新药开发,为基础科学带来全新革命,也标志着AI在生物医药领域的进展进入一个新的阶段。
蛋白质控制着许多人体活动的进行,比如抗体攻击病原体,通过各种酶执行细胞过程。许多严重疾病背后的原因都是由于蛋白质的功能失调。所以要想设计出能与目标蛋白结合的药物,了解蛋白结构极为重要。
以往,科学家们需要从上百万甚至上亿种化合物中层层筛选,再逐步优化,最终确定少数几个候选药物,再进入临床试验,耗时耗力。有了AlphaFold2的预测,将大幅加快新药开发的前期步骤,并降低成本。
AI作为一项工具,如果将它和其他技术结合在一起,将会发挥出巨大的价值。
#架构师成长计划# 第八期AI for Science就讲到了制药公司晶泰科技的案例。
但AlphaFold2当时也存在缺陷。
它强依赖于GPU的并行计算,但GPU又存在严重的显存限制,使得即便是单个显卡最大内存的情况下,能够输入去预测的蛋白质序列长度也不足1000氨基酸。
即使在能提供TB级的内存支持的CPU上的运行效率也非常低,会使每天的通量非常小,反而不利于进行深入的长序列预测。
所以基于此,英特尔基于至强可扩展处理器进行了优化。
AlphaFold2提供了完整的端到端蛋白质三维结构预测流程。其工作流程大致可分为预处理、深度学习模型推理、后处理三个阶段:
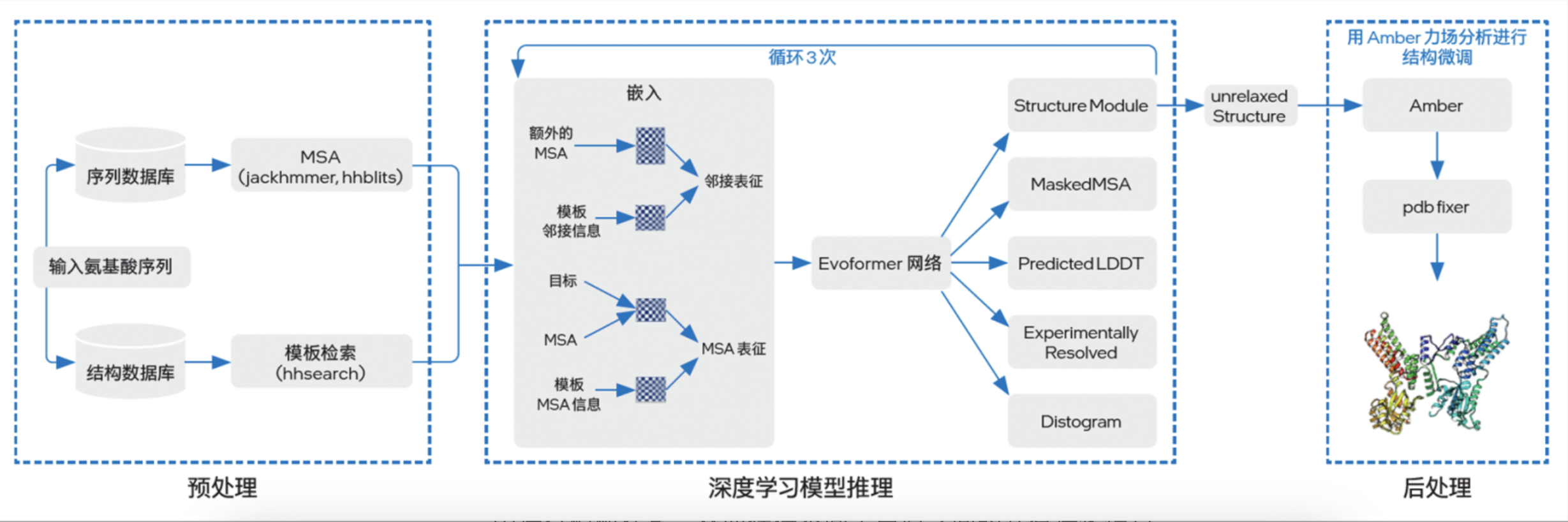
基于第三代至强可扩展平台提供的内置AI加速能力,对于运算和存储性能的均衡设计,以及对硬件和软件协同优化能力的兼顾,英特尔对AlphaFold2进行了端到端的全面优化,优化方案可基本划分为五个步骤:
第一步:预处理阶段-高通量优化
第二步:模型推理阶段-将深度学习模型迁移至面向英特尔® 架构优化的 PyTorch
第三步:模型推理阶段-PyTorch JIT
第四步:模型推理阶段-切分 Attention 模块和算子融合
第五步:模型推理阶段-破解多实例运算过程中的计算和内存瓶颈
英特尔还注意到,内存的容量是限制AlphaFold2发挥潜能的另一个重要因素。在面向不同蛋白质的结构预测工作中,序列长度越长,推理计算复杂度就越大。
受限于产品规格、主板架构和成本,仅使用传统DRAM(Dynamic Random Access Memory)内存很难实现TB级的大容量部署。傲腾持久内存方案是破解这一难题的有效途径,能为方案提供大容量和高性价比的内存支撑,还能输出接近DRAM内存的性能表现。
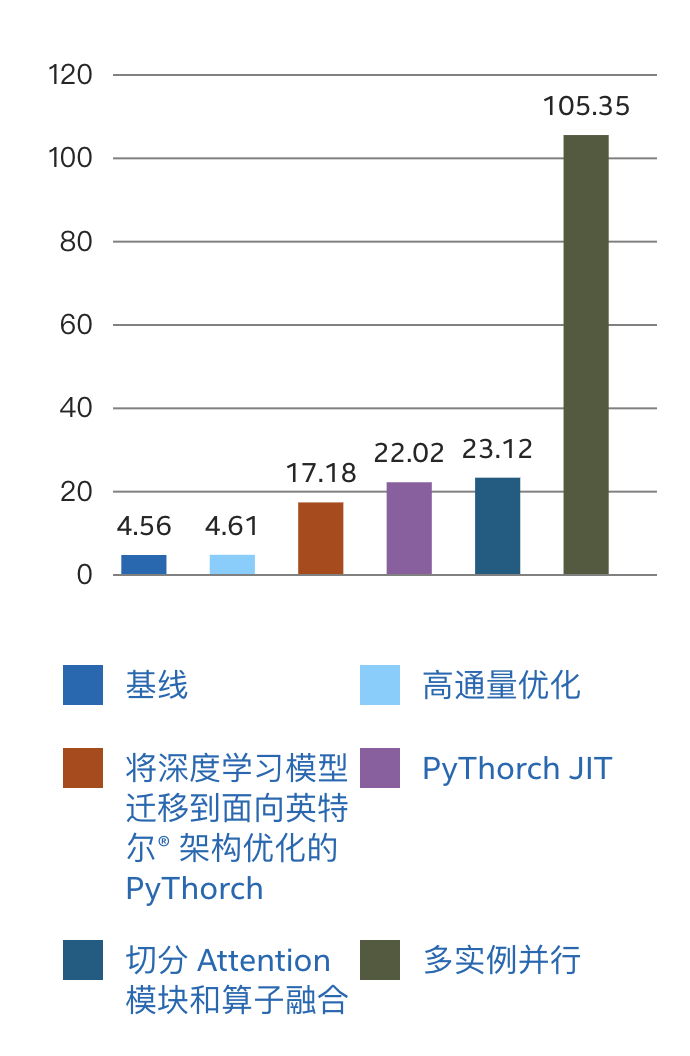
通过以上的优化流程,相比优化前的通量提升可达23.11倍 。

得益于AI技术的高速发展和演进,它与科学前沿研究的结合正在快速地改变世界并造福人们的生活。以AlphaFold2为例,虽然其问世时间不长,但已经有生物学家将其应用到对抗新型传染病和其他疾病的研究中。
面向未来,希望能有更多的科技公司提出和践行“科技向善”的解决方案,在更多层面助力和加速“AI +Science”的技术创新,让AI应用为各类前沿科学研究和探索带来更多加速、助力与收获。
希望英特尔也能以无处不在的连接、无所不在的计算、从云到边缘的基础设施、人工智能、传感和感知这五大超级力量,为全球的数字化变革注入动力。
参考资料: