
人工智能的热度其实并没有降温,而是更多的随着应用具体化从“高大上的、好玩的”案例转向了更加接地气的实际的工业案例。我们的注意力也从当年关注的各种棋牌、对抗类游戏转向了如何应用人工智能来提升我们的生活品质以及工业生产。
而在实际的以面向工业界的案例来说,我们的侧重点和纯粹的研究其实有很大的不同。我最近在观看2022英特尔On技术创新峰会中(Intel Innovation)也有了不少关于这方面的思考。英特尔作为硬件龙头企业,分享了很多关于AI创新方面的思考。其中我很认同的一点就是现阶段我们应该更加关注AI应用的部署问题,尽量提供端到端的解决方案,打通从数据、模型、部署以及后期维护的全链条问题。而在实际应用中,我们应该把重点放在提高生产力,而非绝对的提高模型性能以及算力上去。这个观点在吴恩达的Machine Learning Yearning(https://info.deeplearning.ai/machine-learning-yearning-book )也提到过,那就是工业届智能系统的落地不会为了微弱的精准度提高而使用更昂贵和复杂的模型。因此在这个回答中,我也会围绕我观察到的案例谈谈我对于人工智能创新,尤其是落地部署上的一些思考。
第一点是AI落地对于算力的需求有所不同。举个简单的例子,比如当年非常吸睛的AlphaGO围棋AI 算是第一个出圈的人工智能应用。但在2015年底训练一个分布式版本的AlphaGo他们使用了1,202块CPU及176块GPU。这大概是什么概念呢?基本上就是说当时的任何中小企业,甚至大型企业都几乎不可能在日常的生产和产品上使用这么“昂贵”的人工智能模型。
而实际工业界生产中其实更加合理的思路还是用更加全能和划算的CPU进行处理人工智能任务,可以实现成本和效率上更好的平衡。
比如对于大部分制造企业来说,现阶段较好的人工智能升级路径是使用「云边协同」,也就是把复杂的模型放在云端,而边端(如生产线)负责采集和简单处理。以物联网巨头京东方为例,他们就和硬件龙头企业英特尔一起打造了一套完整的基于云边协同的人工智能智能系统进行生产线上的品控(见下图)。比如他们的边缘处理器使用了英特尔至强CPU处理器作为其边缘服务器的核心计算引擎,而这款处理器集成了更多的核心和高速缓存,非常适合在边端对深度学习推理任务中的密集计算提供特定硬件加速支持。同时这里基于CPU的人工智能解决方案更能带来生产力—它的通用性更容易支持这种 “定制化”的任务和多台机床。而相较于基于CPU的解决方案, 学术界常见的GPU通常更适合处理特定的、模块化的任务,这在人工智能落地上还需要更多的开发工作。
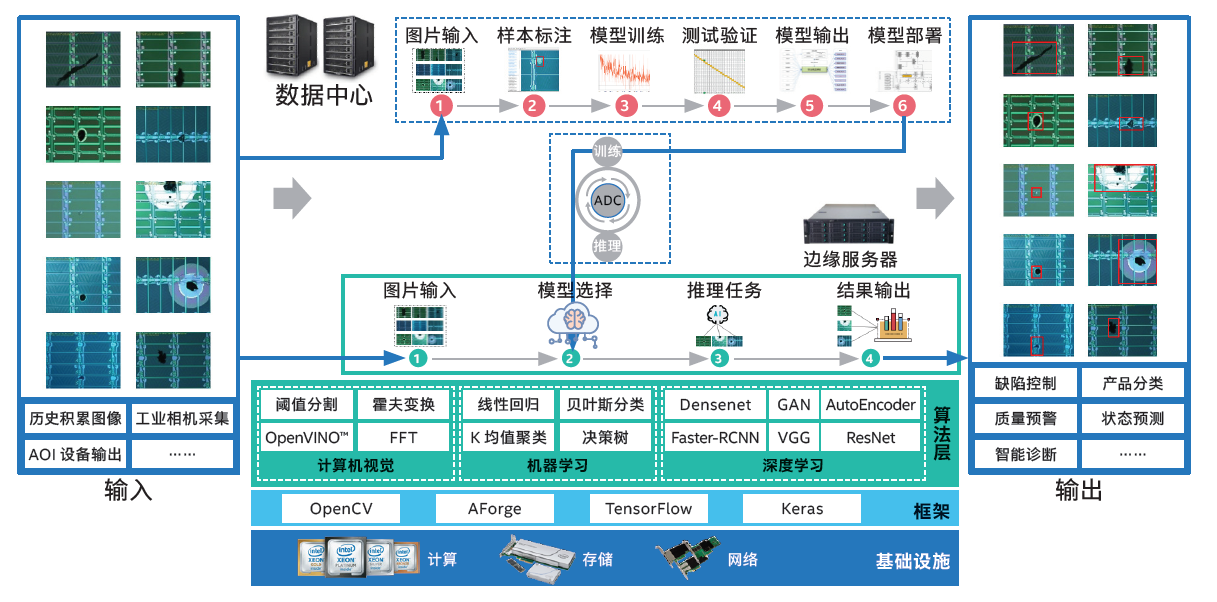
而类似的将人工智能运用于工业界生产的案例还有很多,比如电池生产商宁德时代使用人工智能技术进行电池缺陷检测。简单来说,人工智能技术中有一个方向叫异常检测,主要是用于检测数据中的异常。而异常检测可以直接用于检测宁德时代生产的电池的良品率,大概就是说通过传感器返回的图像决定当前产品是否属于缺陷品。在和英特尔的合作下,他们打造了一套基于英特尔至强可扩展平台产品组合的解决方法,并提出了一个计算机视觉(CV)、深度学习(DL)和机器学习(ML)技术的 AI 电池缺陷检测方案。同时,英特尔还针对宁德时代“CV+DL+ML”混合模式的创新型缺陷检测方案,在其选用模型、训练方法、数据标注及模型调优等方面提供了全面支持,使基于AI技术的缺陷检测方案进一步提升了训练准确率,并使检测准确率和瑕疵找回率都超过了99%。
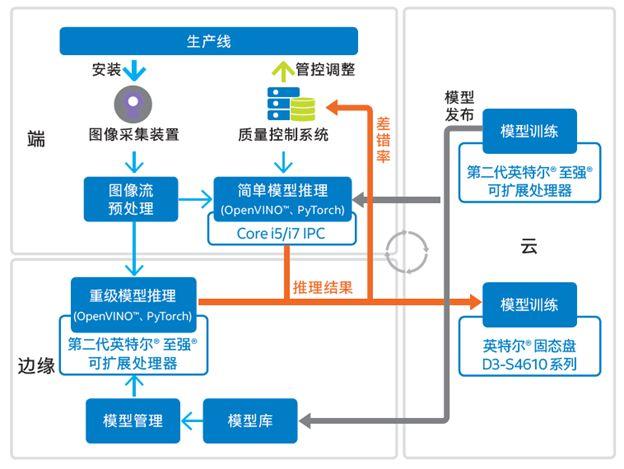
因此京东方和宁德时代的案例都体现了工业界的人工智能落地应该因地制宜,最大化的使用硬件和软件系统实现生产力的提升。而一体化的例如基于英特尔CPU的解决、加速方案,可以在成本和效能上达到较好的结合。
第二是现阶段的AI创新更加在意平台架构和应用上的交汇或融合,也就是在部署上更加在意“一条龙”和完整性,而非只在意模型本身。对于像京东方和宁德时代这样的案例来说,他们需要一个端到端的平台或管线,来完成从数据收集、清洗、处理、再到数据准备,然后是导入高质量数据支持AI应用运转的需求。因此解决思路的完整性,也是人工智能应用的重中之重。在上面的案例中,京东方和宁德时代收集了大量的历史图像和工业相机采集的信息。因此工业视觉平台是这些全新AI缺陷检测解决方案的核心系统,并通过分布式部署来减缓处理压力。但分布式推理经常会遭遇衔接不畅的问题。为解决这个问题,宁德时代以统一的大数据分析及 AI 平台来应对,同时选用了面向英特尔架构优化的PyTorch深度学习框架进行 AI 处理,以及英特尔开源的OpenVINOTM 工具套件来进一步加速 AI 推理性能。而在京东方的框架中也使用到了OpenVINOTM 工具套件来加速人工智能模型的运算。
而针对硬件的软件优化不仅仅只有OpenVINOTM ,英特尔还有开源的基于CPU的TensorFlow优化版本。他们设计的开放的跨架构编程模型oneAPI,将发布包括42种工具的2023工具包,支持英特尔即将推出的全新CPU 、GPU和FPGA架构。同时还有最新的英特尔Geti 计算机视觉平台助力简化AI模型。在使用Geti的场景下,下游的开发团队不再需要大型数据集,只需运行小型训练工作负载就能完成模型构建。同时Geti还可以和OpenVINOTM 相结合,进一步解决计算机视觉AI方案的部署并提高生产力。

因此,我认为“一条龙的AI模式”是创新的重点,且需要软硬件结合以及综合优化。
第三个我关注的创新趋势是考虑到数据的隐私性保护和安全,而最为流行的框架是联邦学习(federated learning)。比如在金融和风控领域,我们希望使用AI从各个渠道收集各种各样的信息,再做出联合预测。联邦学习主要解决如何合法合规的打破信息孤岛 ,在不直接交换和收集信息的前提下实现数据的共同利用。而在这种框架下,隐私保护的重要性其实超过了纯粹的对于深度学习的计算,因为现阶段很多工业界应用的联邦学习方案其实是基于比如集成树模型,因此CPU往往因为其灵活性已经可以实现很好的效果。
我最近看到的一个创新案例是AOK(德国规模最大的医疗保险公司之一)和英特尔合作的AI+保险用户信息分析的案例。首先在保险服务商他们自身都有大量的数据资产,比如患者的多种类个人信息。而打通数据孤岛,并联合的使用这些信息进行人工智能建模,不仅可以可以给用户提供更精准的预测,也可以降低保险欺诈为企业挽回损失。因此如何使用联邦学习打通多中心之间的数据共享就变得特别重要。
而AOK在使用英特尔软件防护扩展(Intel Software Guard Extensions,简称为 SGX)的框架下,为用户信息导入基于硬件可信执行环境(Trusted Execution Environment,TEE)的联邦学习方法,为医疗保险分析中参与多方计算的敏感数据和代码提供更为可靠的安全防护,从而在根本上防止了大家担心的隐私泄露和安全问题。
下图提供了英特尔® SGX如何在多间银行间协同分享数据并训练人工智能模型的示意图,而其中每个本地的设备上的SGX确保了数据的安全性。简单来说,英特尔® SGX 能在内存的特定硬件环境中构造出一个可信的安全 “飞地”(Enclave),为人工智能学习过程中参与多方计算的敏感数据和代码提供更强的安全防护。这种为敏感和加密数据构建硬件隔离的方法可以大幅度提升安全性,但从成本和硬件角度来看也只有像英特尔这样的硬件厂商才最适合进行开发和部署这样的解决方案。
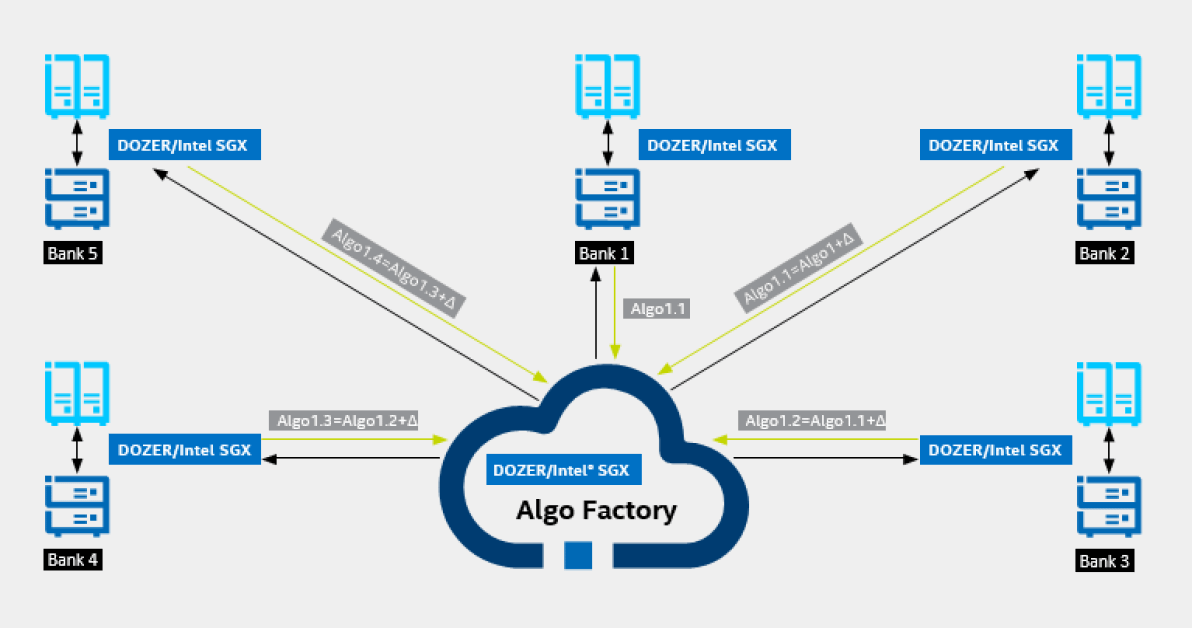
基于英特尔SGX的联邦学习方案—可以安全的在多个数据提供源上进行协同学习
因此回到主题。我认为AI创新的步伐并没有变缓,而是从专注于趣味应用转向了在更实用的角度上研究如何更好的落地。而其中的重点包括但不限于对算力和生产力的更深刻的理解,对于一体化AI模型部署的探索,以及更好的对于数据隐私的保护。
而除了这些人工技能落地的发展以外,另一个有趣的发展方向是AI for Science。也就是如何用人工智能来解决其他学科的科学问题,包括但不限于生物、化学、物理、数学等。其中最为引人注目的就是谷歌旗下DeepMind推出的人工智能驱动的蛋白质折叠模型,解决了生物学领域50年来的重大难题。而如何培养我们的AI创新能力,感兴趣的朋友也不方便关注一下英特尔与际学术期刊《科学》(Science/AAAS)联合出品的「架构师成长计划」公益课程,从实践的角度把握AI架构的前沿经验。在这一系列前沿公开课中,他们不仅会分享人工智能落地的经验与实践,也会共同探讨前沿的科学问题,比如生物医药领域中计算模型的发展与应用,为相关领域的架构师们答疑解惑。