
唔……事情到了这种程度,公众得出的共识,基本上已经转化为武汉大学要死保杨景媛。为什么要死保杨景媛?我的猜测是,杨景媛不仅是豆瓣小组的成员,而且等级应该不低,或者说,豆瓣小组的一个核心小组,建立在武汉大学,所以武汉大学只能支持杨景媛。
为什么这么说呢?
我们可以看看这个问题:

那么如这个问题所示,我们可以发现,在8月3日左右,豆瓣生活组组织策划对肖同学进行了大型的网络攻击:

不过关于豆瓣小组,有一点必须要进行补充,这也是一个简单的信息差:豆瓣小组大规模投入于社会事件,特别是在性别矛盾里进攻的时候不多,最近的时间里,除了去年的肥猫案,就只有今年的武汉大学图书馆事件。
那么我们可以关注这个时间点,这个时间点有什么深意呢?
我们还可以看看PNAS在2016年8月的这篇文章,实验基于一个纵向高分辨率数据集,该数据集描述了欧洲一所大型大学中大约1000名新生的密集联系群体。
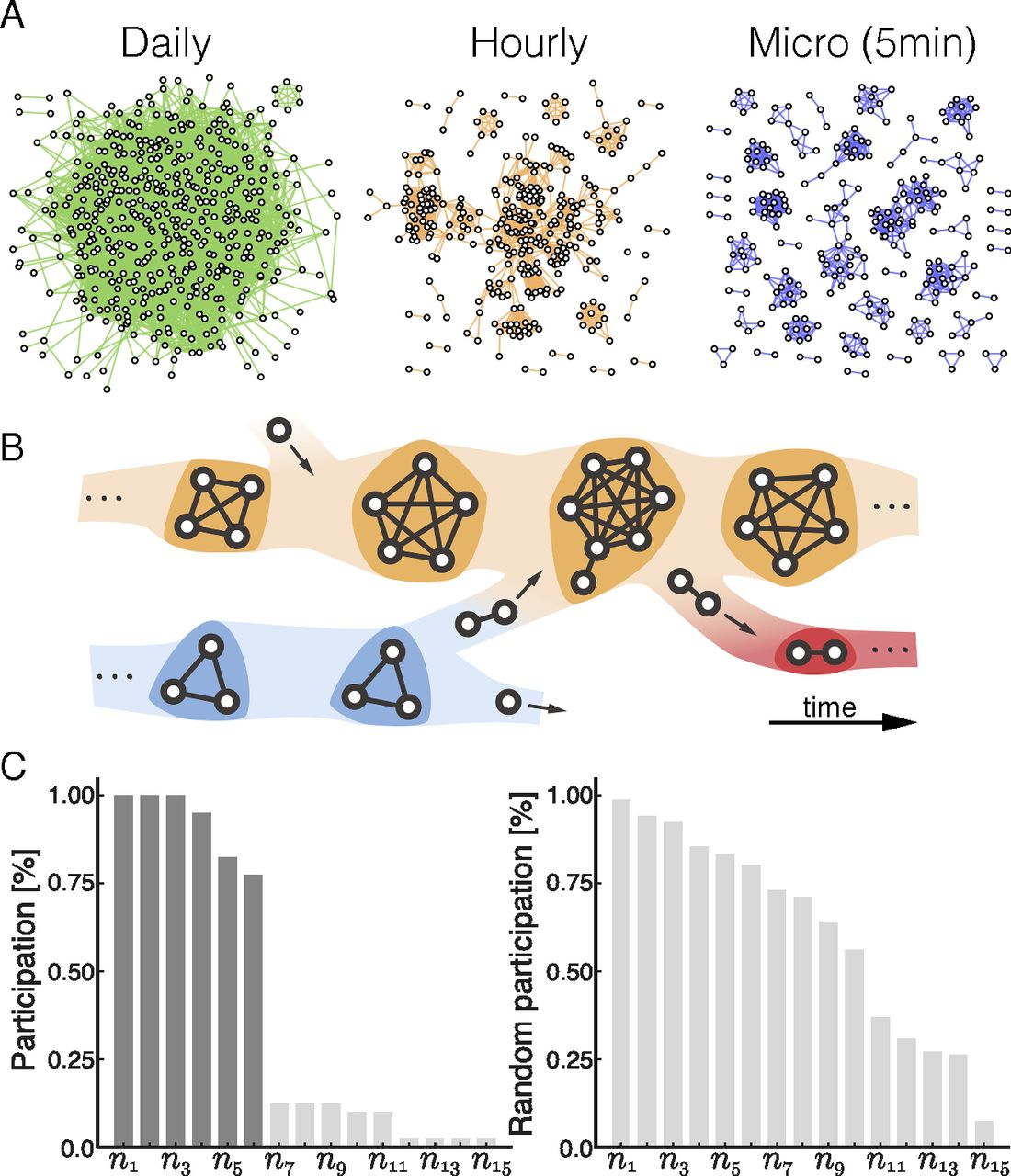
唔姆,如图所示,a图表示不同时间尺度上的社交网络。由 1 天(绿色)、60 分钟(橙色)和 5 分钟(蓝色)时间聚合内的面对面会议形成的网络。在 5 分钟的时间片段中,可以直接观察到群组而没有太多歧义,但随着时间在各个箱体中聚合,群组之间的重叠会增加。b图表示聚会动态说明。随着成员在社交环境中进出,聚会逐渐发展。c图从参与概况中提取核心。深灰色条表示参与水平高于最大差距的节点。
在物理邻近网络中,会议要求所有成员同时出席,并且他们在物理上距离很近。物理会议的这些特性意味着聚会可以直接识别为每个5分钟时间片内的图形组件。节点可能在每个时间步骤中只属于一个聚会,但随着时间的推移,个人会进出社交聚会,改变他们的从属关系并形成新的聚会,如B图所示,聚会在规模和持续时间方面都表现出广泛的分布,涵盖了从小团体到大型聚会、从几分钟的短暂互动到持续数小时的长时间会面的各种会议,涵盖了各种会议类型。
聚会代表一群人之间一次会面的时间演变。然而,在大多数情况下,聚会是持久社交环境的一个实例,我们观察到相同的节点参与了随后几天、几周和几个月的重复聚会,将与同一组人的所有聚会相对应的社会结构称为“核心”。那么核心有什么特征呢?
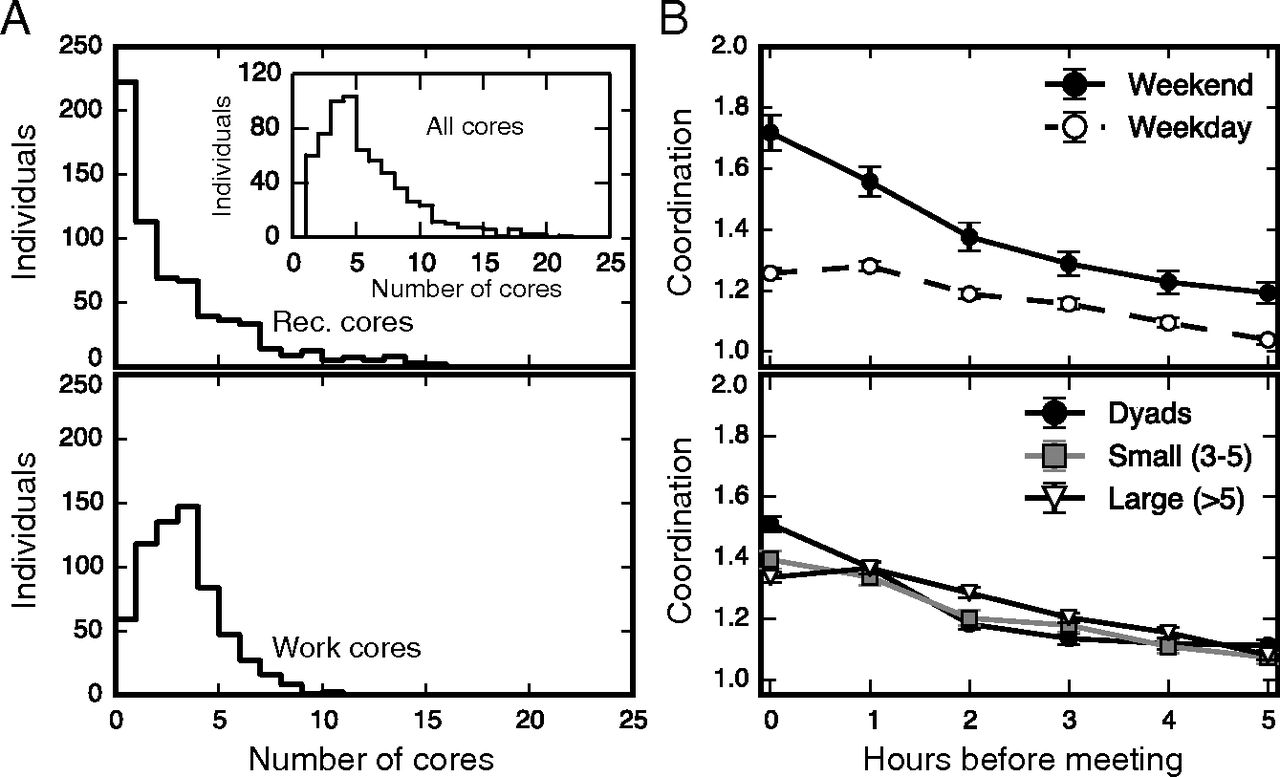
唔姆,如图所示,a图表示工作和娱乐核心成员的分布,b图表示会议前的协调定义为会议前每小时时间段内发生的电话和消息的增加,相对于基于每个参与者平均每小时电信行为的空模型。虽然每个人的娱乐核心数量分布很广泛,但大多数参与者只属于一两个娱乐核心。每个人的工作核心分布是局部的,每人的工作核心大约在1~4个上下。
除此之外,我们还可以关注群体中个人普遍的行为轨迹。
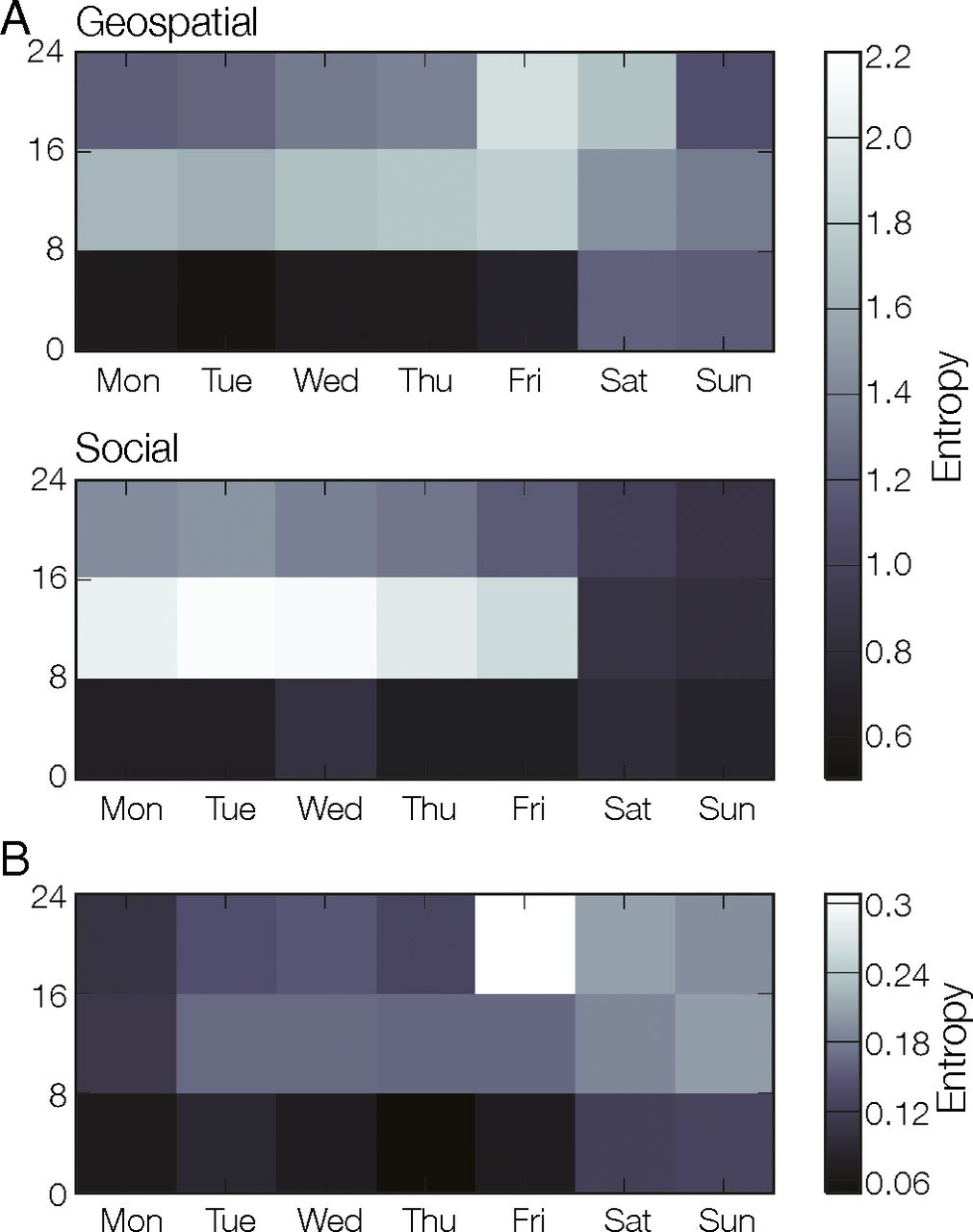
唔姆,如图所示,a图表示位置(上)和社会(下)状态的不相关熵,对所有个体取平均值,显示一周内个体在 8 小时内的不可预测性。b图表示核心的地理空间熵,表示核心何时探索新的地理空间位置。
地理空间行为的特点是工作日晚上的熵值较低,基本上相当于在一两个地方睡觉。工作日的熵值较高,大多数晚上的熵值处于中间值,但周五和周六晚上是个例外,这两个晚上的熵值是整个星期中最高的。这些“聚会之夜”始终是平均地理空间熵最高的时间段,对应于探索行为。
社会行为与一周中大部分时间的地理空间行为相似:可预测的夜晚、变化的白天和介于两者之间的傍晚。然而,在周五和周六晚上,社交轨迹表现出的行为与地理空间轨迹产生的集体模式有显著不同。在这些时间段内,当研究参与者在地理空间意义上最具探索性时,参与者在社交意义上似乎非常保守,表现出更简单、更可预测的社交行为,也就是说,绝大多数参与者将校外生活集中在少数社交核心上。
上述观察结果表明,在一周内,人群的特点是同一群人会聚集在同一个地方,探索活动在周五晚上和周末达到高峰。在周五晚上和周末,人群的地理空间行为最不可预测,同一群人的社交行为往往非常可预测,他们会探索一系列地点,但总是和同一群核心朋友在一起。[1]
回到这个问题,我们从去年开始,两次通报的时间都是在周末的晚上,符合群体个人在周末晚上具有高活跃性,以及社交核心简单的特征。我们可以简单预估一下形式:这些媒体在写好新闻稿后,选择在周末晚上发布,然后事先从饭圈这边调集大量只具备简单社会行为,也就是刷数据的数据女工,在短时间内刷出自己想要的数据,确保第一时间能引领风向。也就是说,这个群体以大学生和硕士为主。
而在武汉大学图书馆事件里,也表现出了类似的规律:在周末晚上,大量豆瓣小组的成员突然发难,在短时间内,和饭圈相结合,对肖同学进行大批量的攻击。
结合以上的信息,我们自然能推出一个猜测:杨景媛的豆瓣小组,一个核心节点建立在武汉大学,或者换句话说,武汉大学的对外宣传的方面,至少一大半都支持杨景媛,甚至可以说,在事件爆发前就支持杨景媛。
那么杨景媛在武汉大学搭建完豆瓣小组后,会表现出什么特征呢?
我们可以看看science在2015年7月的这篇文章,里面说的是社交媒体和意见极化之间的关系。
实验使用了来自Facebook的大型综合数据集,该数据集能够比较Facebook上分享的大量新闻和观点与个人朋友网络分享的大量新闻和观点的意见多样性,将其与个人算法排名的新闻提要中出现的故事子集进行比较,以及观察个人在新闻提要上曝光后选择消费哪些信息。实验构建了一个去识别数据集,其中包括1010万名美国活跃用户和美国用户在2014年7月7日至2015年1月7日的6个月期间分享的700万个不同的网络链接。我们通过在一元、二元和三元文本特征上训练支持向量机,将故事分为“硬”内容(如时事内容)或“软”内容(如体育、娱乐或旅游)。
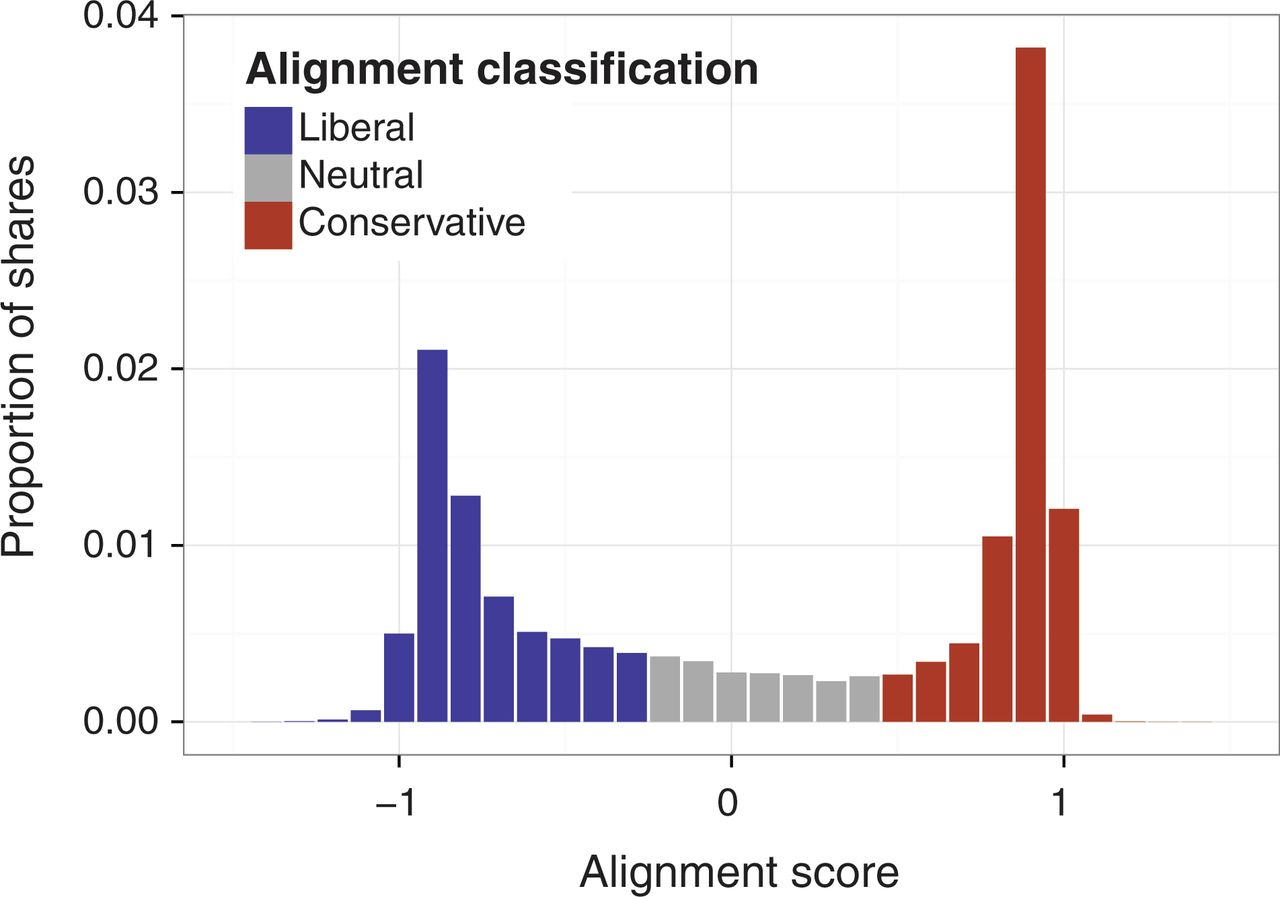
唔姆,如图所示,以上是Facebook 上分享内容的意见倾向性分布,以分享者的平均归属程度按分享总数加权来衡量。实验通过计算分享文章的每位用户的意见倾向的平均值,获得了每篇硬新闻的内容一致性指标。一致性不是衡量媒体倾向的标准,而是捕捉一组回声室之间分享的内容类型的差异,包括主题、框架和倾向。结论很明显,我们观察到用户分享的硬新闻内容存在显著的两极分化,最常分享的链接显然与自由或保守人群结盟。
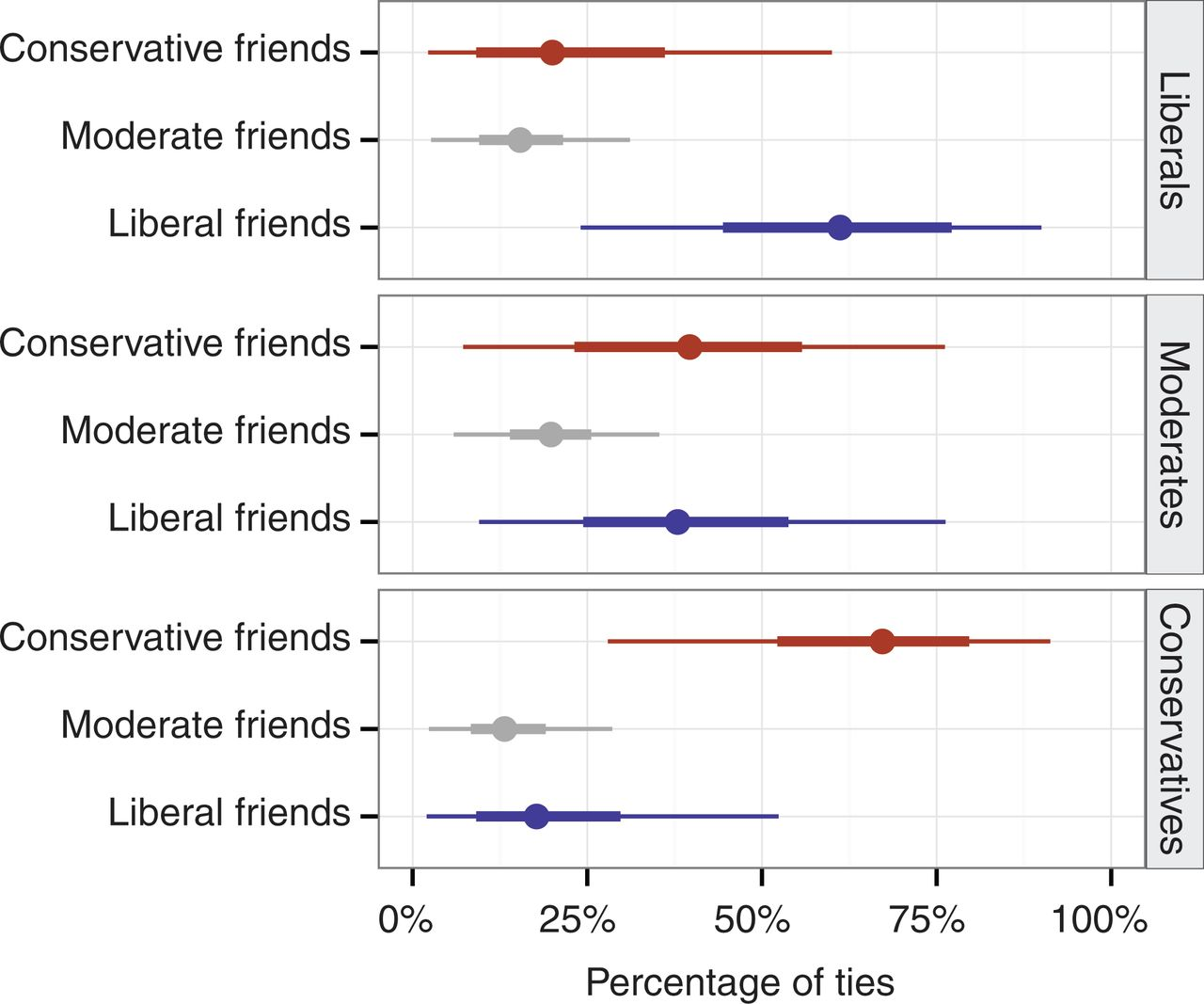
唔姆,如图所示,以上是自我报告的意见归属同质性,以及自由、温和和保守用户与不同意见形态的好友的链接比例。结论也很明显:Facebook上的信息流由网络中个体的连接方式构成,Facebook上的人际网络不同于博客的结构。尽管Facebook上存在根据意见倾向而聚类的情况,但也存在许多跨越意见倾向的友谊。
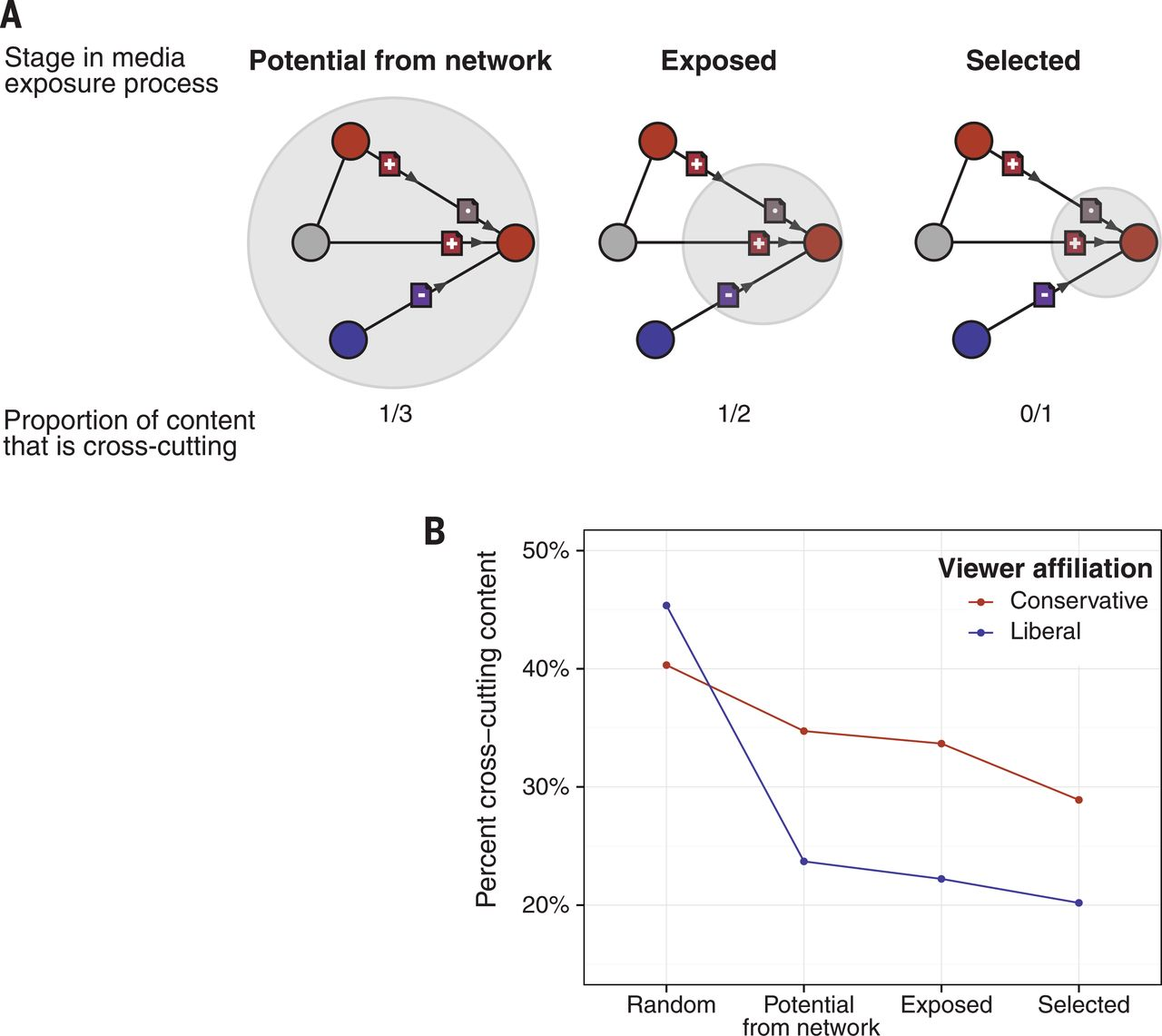
唔姆,如图所示,以上是扩散过程各阶段的交叉内容。(A) 图说明算法排名和个人选择如何影响个人遇到的意见交叉内容的比例。灰色圆圈表示媒体曝光过程每个阶段的内容。红色圆圈表示保守,蓝色圆圈表示自由。(B) 图表示内容的平均意见多样性由随机其他人分享、由朋友分享、实际出现在用户的新闻提要中以及用户点击。结论很明显,个人在Facebook上消费的媒体不仅取决于他们的朋友分享的内容,还取决于新闻提要排名算法如何对这些文章进行排序以及个人选择阅读的内容。用户在News Feed中看到故事的顺序取决于许多因素,包括浏览者访问Facebook的频率、与某些好友的互动频率以及用户过去在News Feed中点击某些网站链接的频率。我们发现,经过排名后,平均而言,交叉内容略有减少。
除此之外,个人接触到多少交叉内容取决于他们的朋友是谁以及这些朋友分享了哪些信息。如果个人从随机其他人那里获取信息,倾向自由的人群中接触到的硬内容中约有45%是交叉的,而保守接触到的硬内容中有40%是交叉的。
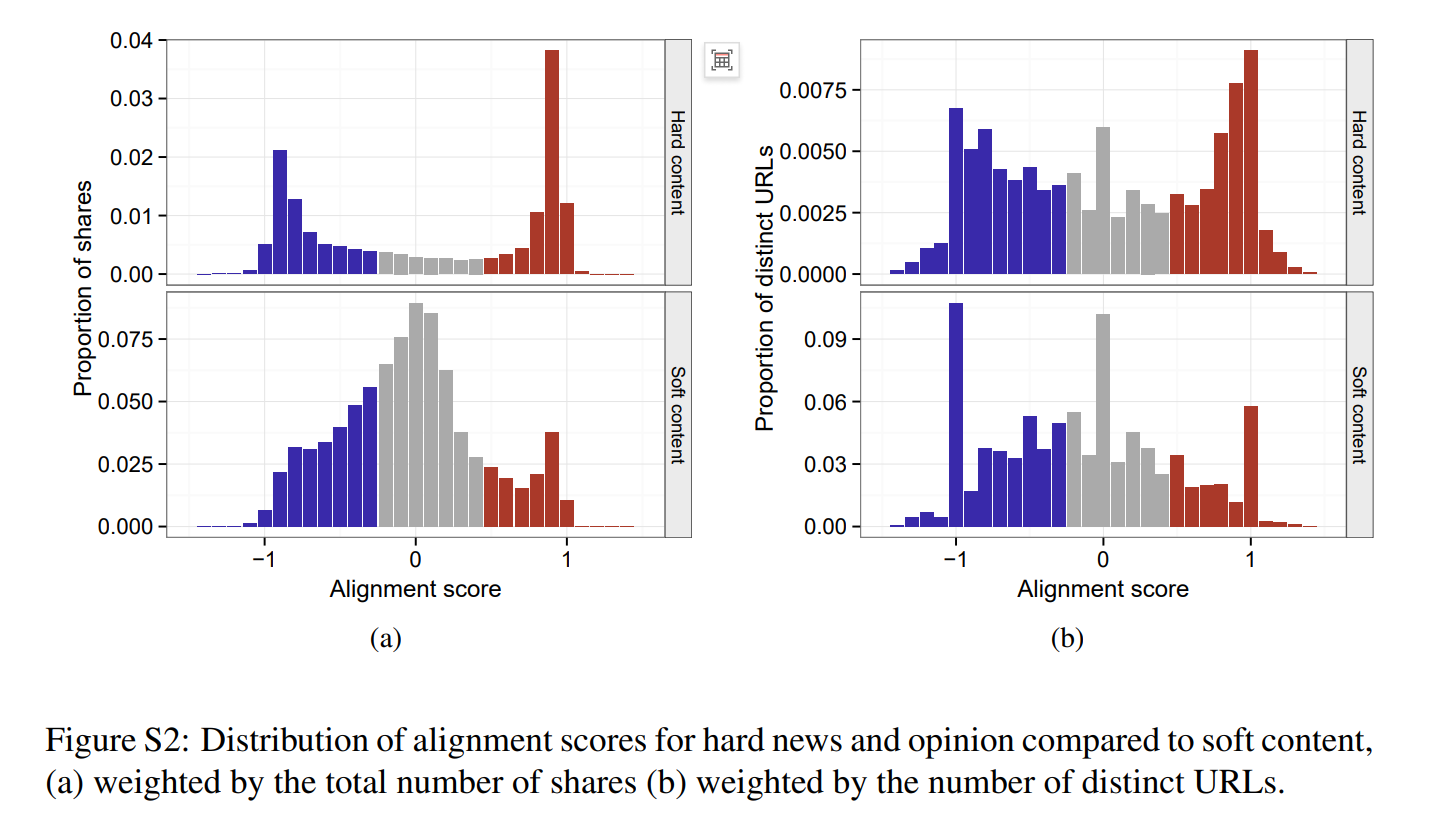
唔姆,如图所示,以上是硬新闻和观点与软内容相比的一致性分数分布,(a)图表示按分享总数加权,(b)图表示按不同URL数量加权。我们可以发现,在硬新闻中,极化程度总体比较严重,而在软新闻中,极化程度总体比较浅。[2]
总结一下结论,文章的内容很明确,对立的两个原因,一个是朋友之间推荐同质化内容,而缺乏异质化内容;一个是通过算法,让人群倾向接触和自己观点一致的内容。顺便补充一句,对立的前提,是有不同意见才叫对立,如果双方都支持该意见,那么就不是对立,而是共识。比如我现在说“温柔的思辩姐姐是樱小路露娜”,有不同意见吗?没有,那么“温柔的思辩姐姐是樱小路露娜”就是共识。
回到这个问题,我们能发现什么呢?

就这篇文章,我们可以看出一点,武汉大学此时已经陷入了一个严重的信息茧房中,所以才会出现大量武汉大学学生支持杨景媛的情况。
如果你对这个结论有疑问,那我可以再举一个例子:四川大学张薇事件里,有出现大量四川大学学生支持张薇的情况出现吗?所以,武汉大学这种情况并不是巧合。
因此,现在对于武汉大学而言,如果不尽早处理杨景媛,那么随着时间推移,那么只会越来越深化“武汉大学就是豆瓣大组”的结论。
参考
- ^V. Sekara,A. Stopczynski,& S. Lehmann, Fundamental structures of dynamic social networks, Proc. Natl. Acad. Sci. U.S.A. 113 (36) 9977-9982, https://doi.org/10.1073/pnas.1602803113 (2016).
- ^Eytan Bakshy et al. ,Exposure to ideologically diverse news and opinion on Facebook.Science348,1130-1132(2015).DOI:10.1126/science.aaa1160