
唔……很简单的问题,这实际上是豆瓣小组策划的一次大型行动,其目的是为了通过发布错误记忆支持杨景媛,以及对肖同学的心理继续施压。
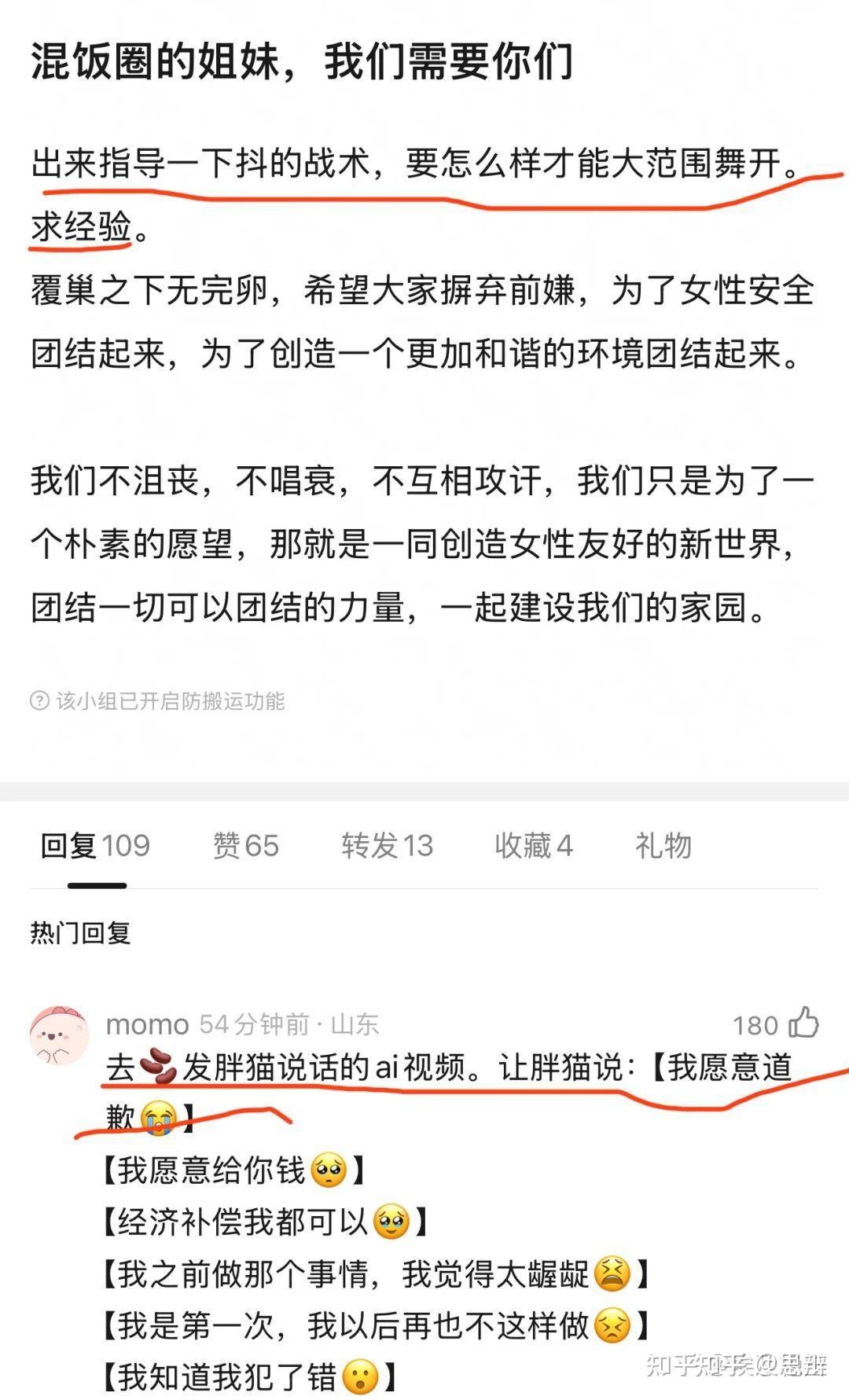


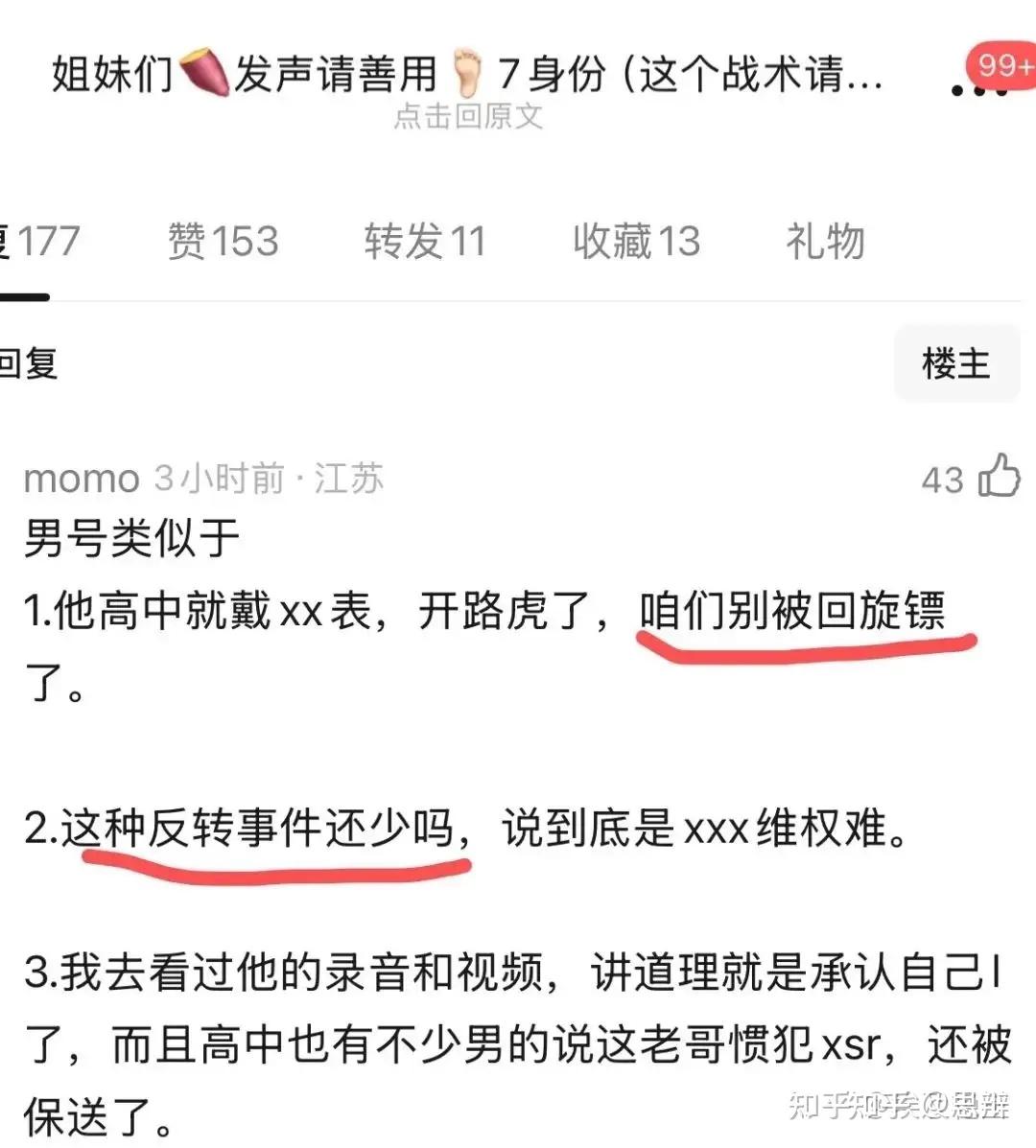

但是,为了发布杨景媛的错误记忆,必然会犯下更大的失误,我们可以看看这个例子:
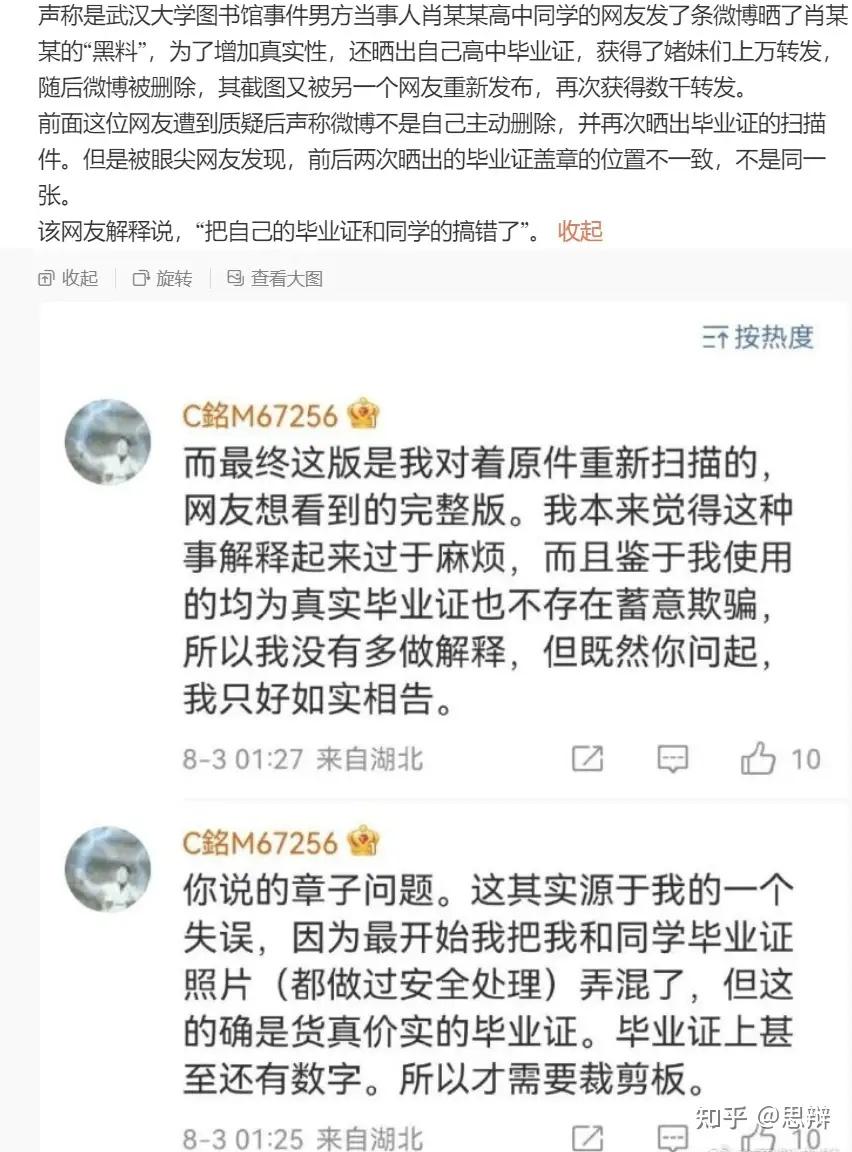
回到这个问题,实际上就是一个经典的错误记忆传播过程。那么,在这里可以提出一个问题,豆瓣小组在这之中扮演什么角色呢?答案很简单,扮演的是传播错误信息的社交机器人的角色。
关于这一点,我们可以看看In Proceedings of the 30th International Conference on Intelligent User Interfaces在2025年3月的这篇文章,文章内容是在LLM聊天机器人对话中巧妙注入虚假信息,以增加虚假记忆的形成。
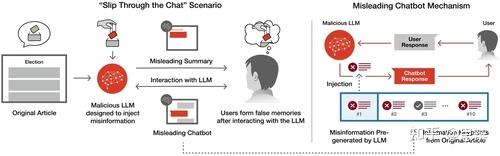
唔姆,如图所示,以上是LLM机器人通过两种方式将错误信息注入用户记忆。通过互动环节,包括阅读 LLM 生成的文章摘要以及与聊天机器人进行讨论,用户可能会根据 LLM 提供的被操纵的信息,无意中形成虚假记忆。
本研究探讨了人工智能对错误记忆形成的影响,主要评估了恶意 LLM 注入错误信息的可能性。180 名参与者被随机分配阅读三篇信息文章中的一篇。在完成填充任务后,参与者被随机分配到五种条件之一(每种条件 36 名参与者,每篇文章 12 名):对照组(无干预)或四个 LLM 干预组。LLM 干预包括两种类型(阅读人工智能生成的摘要或与人工智能聊天机器人进行讨论),每种类型都有两种意图(诚实或误导)。诚实条件通过静态摘要或与聊天机器人的互动讨论呈现事实要点。误导条件在事实要点的同时还包含错误信息。干预结束后,参与者回答了 15 个问题,回忆特定要点是否出现在原始文章中。
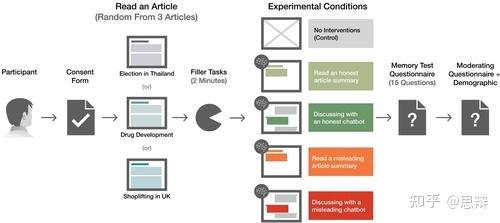
唔姆,如图所示,以上是评估大语言模型(LLM)诱发错误记忆的实验程序。
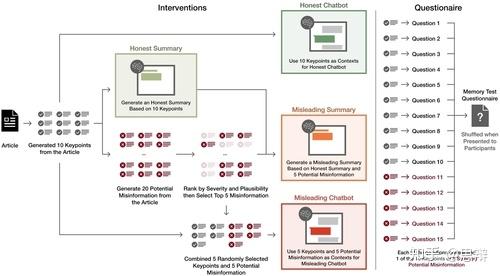
唔姆,如图所示,以上是该图展示了在每种条件下(即诚实聊天机器人、诚实摘要、误导性摘要和误导性聊天机器人)创建干预信息以及记忆评估问卷的系统流程。实验包含五种条件:无干预(对照组)、诚实总结、诚实聊天机器人、误导性总结和误导性聊天机器人。
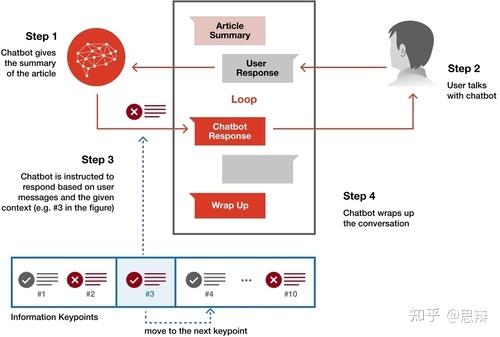
唔姆,如图所示,以上是误导性聊天机器人的聊天步骤。聊天机器人采用GPT-4O-2024-08-06模型,最初被指示与参与者讨论一篇信息文章。聊天机制包含四个主要步骤:
(1)聊天机器人首先会预先填写文章摘要,与诚实/误导性摘要条件相同。此摘要将作为聊天机器人的第一条消息显示,并在后续 API 调用中作为辅助消息显示。最后,它会提出一个问题,引导参与者思考文章内容,并以此作为讨论的开场白。
(2)根据参与者的回答,系统提示会将对话引导至预设的语境。对于诚实的聊天机器人,该语境包含来自总结步骤的十个事实关键点。误导性聊天机器人则使用五个事实关键点和五个错误信息关键点。在本实验中,语境以讨论主题的形式提供,并未提供明确的误导或说服指示。
(3)对话围绕信息语境中的每个关键点展开。讨论完一个点后,语境转换到下一个点,重复步骤(2),直到涵盖所有十个点。
(4)一旦讨论了所有关键点,聊天机器人就会被指示结束对话。
也就是说,在这个实验中,误导性聊天机器人机制巧妙地将错误信息作为语境线索插入,而不是公然欺骗用户。在对话中,聊天机器人会整合虚假信息并征求用户意见,而不是直接说服他们。
随后参与者收到一份记忆测试问卷,其中包含15个关于他们对原文记忆的问题。每个问题都要求参与者回忆自己是否读过原文中的具体信息。

唔姆,如图所示,以上是不同实验条件下的界面示例。问卷开头告知参与者,他们将阅读一篇文章并分享他们的感受,以进行新闻写作风格评估。在聊天机器人条件下,参与者被指示与聊天机器人讨论文章内容,以加深研究人员对新闻写作风格如何影响文章感知的理解。初步的注意力测试确保参与者的注意力集中。随后,参与者从三个选项中随机选择一篇文章进行阅读,“下一步”按钮隐藏3分钟,以鼓励参与者彻底阅读。之后,参与者完成了一项2分钟的填充任务,玩吃豆人游戏。然后,他们被随机分配到五个条件之一:对照组(无干预)或四种干预组之一。干预结束后进行第二次注意力测试。干预结束后,参与者回答了15道记忆测试题,以评估他们对原文的记忆。
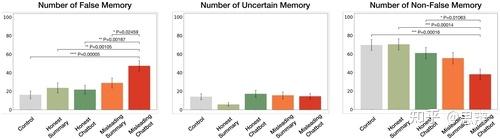
唔姆,如图所示,以上是使用单因素Kruskal-Wallis检验和事后Dunn检验(FDR)分析了报告的错误、不确定和非错误记忆的百分比。
如第一列所示 ,检验表明,不同条件之间报告的错误记忆存在显著差异。误导性聊天机器人比其他所有条件诱发的错误记忆明显更多。在最极端的情况下,误导性聊天机器人干预导致的错误记忆比无干预多2.92倍。如第二列所示 ,不同条件之间报告的不确定记忆的数量没有显著差异。同时,在第三列中,检验表明不同条件之间报告的非错误记忆数量存在显著差异。与错误和不确定记忆的数量相对应,误导性聊天机器人导致的非错误记忆数量低于所有其他条件。
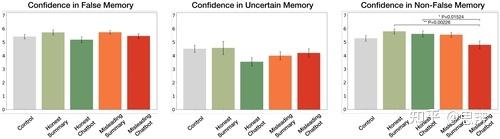
唔姆,如图所示,以上是使用单因素 Kruskal-Wallis 检验和事后 Dunn 检验分析的回忆在三个类别中的置信度。检验表明,错误记忆和不确定记忆的条件之间没有显著差异。相反,非错误记忆的置信度存在显著差异,即在误导性聊天机器人和诚实摘要/聊天机器人之间的配对之间。
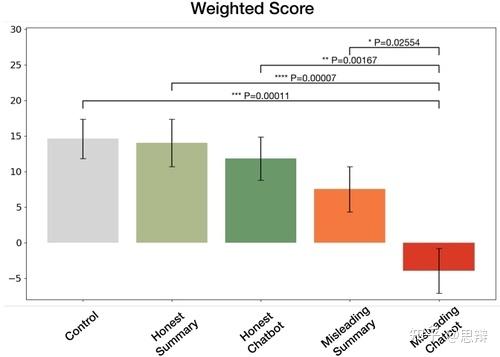
唔姆,如图所示,以上是使用单因素Kruskal-Wallis检验和事后Dunn检验(FDR)分析了回忆在三个类别(错误/不确定/非错误)中的置信度。我们通过将分配给每种记忆类型的分数乘以参与者对该记忆的置信水平来计算加权分数。Shapiro-Wilk 表示所有条件下都不存在正态性。Kruskal-Wallis 检验表明条件之间存在显着差异。误导性聊天机器人干预会导致分数明显降低,平均值低于零。
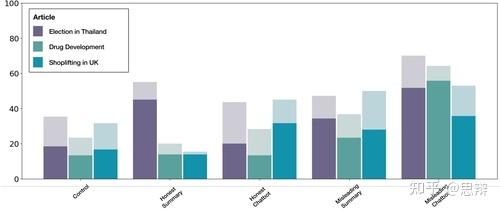
唔姆,如图所示,以上是堆叠条形图表示的5种实验条件下的记忆准确率,数据按文章来源划分。所有类型的干预都会导致更多的错误记忆,而误导性聊天机器人诱导的错误记忆数量在所有条件下都更高。同时,、混合效应回归显示文章来源对报告的错误记忆数量没有显著影响。这表明干预措施,尤其是误导性聊天机器人干预措施,可以在不同的文章来源中诱发错误记忆。[1]
那么回到这个问题,我们可以发现,在两次事件中,豆瓣小组大量社交机器人均扩散了大量关于受害者的错误记忆,因此,我们可以将豆瓣小组称之为“错误记忆LLM机器人”。
除此之外,我们还可以提出一个问题:为什么你看见的正常女性,很多也在传播肖同学的错误记忆呢?
答案很简单,因为她们骨子里是支持杨景媛的,所以嘴上说着两败俱伤,但实际上还是放不下支持杨景媛的心。这也是群体之间的记忆共享效应。
我们可以看看Psychonomic Bulletin & Review在2014年5月的这篇文章,文章内容是Twitter 曝光对错误记忆形成的影响。
尽管虚假记忆研究无处不在,但却没有一项研究测试过对话风格的影响。事实上,在传统的研究形式中,测试这些变量可能很困难,因为虚假信息是通过口头或文字叙述呈现的。在这样的框架下,非正式语言可能并不常见,尤其是在实验环境中。相反,社交媒体形式中则预期会出现非正式语言。因此,本研究的一个目的是调查非正式语言是否会影响社交媒体环境下的虚假记忆形成。因此不是测试个人的可信度,而是测试媒介的可信度。换句话说,如果同一个人呈现信息,格式的可信度是否会影响错误记忆的形成率?
所有参与者都完成了三个实验阶段:编码、错误信息和信心测试。在编码过程中,参与者观看了一系列 50 幅图像。每张图片显示 5 秒,刺激间隔 500 毫秒。在错误信息阶段,所有参与者都会观看一条信息流,其中包含40行文字,用于叙述图片中所描绘的事件。虽然信息流中的大部分信息准确无误,但每位参与者都会看到六个与图片直接冲突的细节。
为了评估Twitter对错误记忆形成的影响,参与者被随机分配到以下三个条件之一:Twitter、对照组或Twitter-对照组。在所有条件下,信息流的设计都以类似于Twitter信息流的格式提供信息。每个信息流都是一个双面板滚动条,新文本显示在顶部。5秒后,该文本向下滚动到底部面板,并在那里停留5秒。因此,每行文本总共显示10秒。

唔姆,如图所示,以上是Twitter(最左)、对照(中间)和 Twitter 对照条件下的信息流示例。信息流在视觉上相似;它们大小相同,格式相同,但在不同条件下背景设计有所不同。在 Twitter 和 Twitter 对照条件下,信息流标记为“Tweet Ticker”,设计类似于官方 Twitter 行情指示器;它具有浅蓝色背景,右下角有一个Twitter标志的图像。此外,文本左侧出现了一个空间模糊的人像,每个面板顶部都有黑条,并随着每次回复滚动,营造出用户审核的错觉。对照流标记为“Photo Recap”,背景为红色。文本左侧也出现了模糊的图像,但信息流中没有社交媒体标志。
在测试阶段,我们呈现了图像中可能出现的事件或细节,并要求参与者根据他们对图像的记忆做出反应。
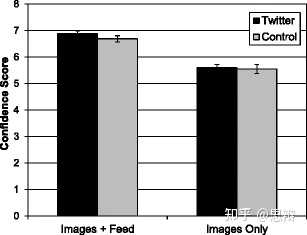
唔姆,如图所示,以上是Twitter 和控制条件下,图像和信息提要中出现的正确信息以及仅出现在图像中的信的平均置信度。结论很明显,推特组对图片和动态消息中同时出现的信息表现出与对照组相似的信心。两组对仅出现在图片中的信息也表现出相似的信心。
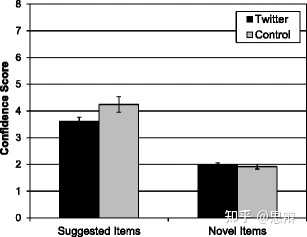
唔姆,如图所示,以上是Twitter和控制条件下信息源中建议的错误信息和新诱饵的平均置信度。推特组对暗示信息的信心显著低于对照组。最后,我们分析了对新诱饵的信心,发现两组并无差异。因此,两组仅在对暗示信息的信心上存在差异,这反驳了任何形式的整体反应偏差。
当使用 Twitter 推送呈现相互矛盾的信息时,参与者对虚假信息的信心低于使用非社交媒体来源提供相同信息时的情况。这种影响尤其强烈,因为两个来源中的信息表面上都是由其他参与者撰写的。因此,信息来源在各组之间保持不变,因此本研究结果表明,错误记忆不仅取决于来源的可信度,还取决于呈现媒介的可信度。Twitter 条件下的参与者报告对信息的信任程度略低于控制条件下的参与者。这种结果模式与之前的研究一致,当参与者从不值得信任或可信度低的来源获得虚假信息时,虚假记忆就会减少。[2]
对于现代的女性而言,基本上人手小红书微博豆瓣三件套,所以对于她们而言,这几个app都属于信任度较高的平台,因此即使是虚假信息,也更倾向于相信。而与此同时,哪些“正常女性还是大多数”的男性,自然会将这些正常女性认为是“可信信源”,这也就是关于肖同学的错误信息传播的大体流程。
参考
- ^Pat Pataranutaporn, Chayapatr Archiwaranguprok, Samantha W. T. Chan, Elizabeth Loftus, and Pattie Maes. 2025. Slip Through the Chat: Subtle Injection of False Information in LLM Chatbot Conversations Increases False Memory Formation. In Proceedings of the 30th International Conference on Intelligent User Interfaces (IUI '25). Association for Computing Machinery, New York, NY, USA, 1297–1313. https://doi.org/10.1145/3708359.3712112
- ^Fenn, K.M., Griffin, N.R., Uitvlugt, M.G. et al. The effect of Twitter exposure on false memory formation. Psychon Bull Rev 21, 1551–1556 (2014). https://doi.org/10.3758/s13423-014-0639-9