
是这样的。
有位老兄已经将她的错误整理如下了:

除了这些问题,还有一些关于她核心回归模型中(5.1.1)的技术问题的补充:
1、样本量数据对不上
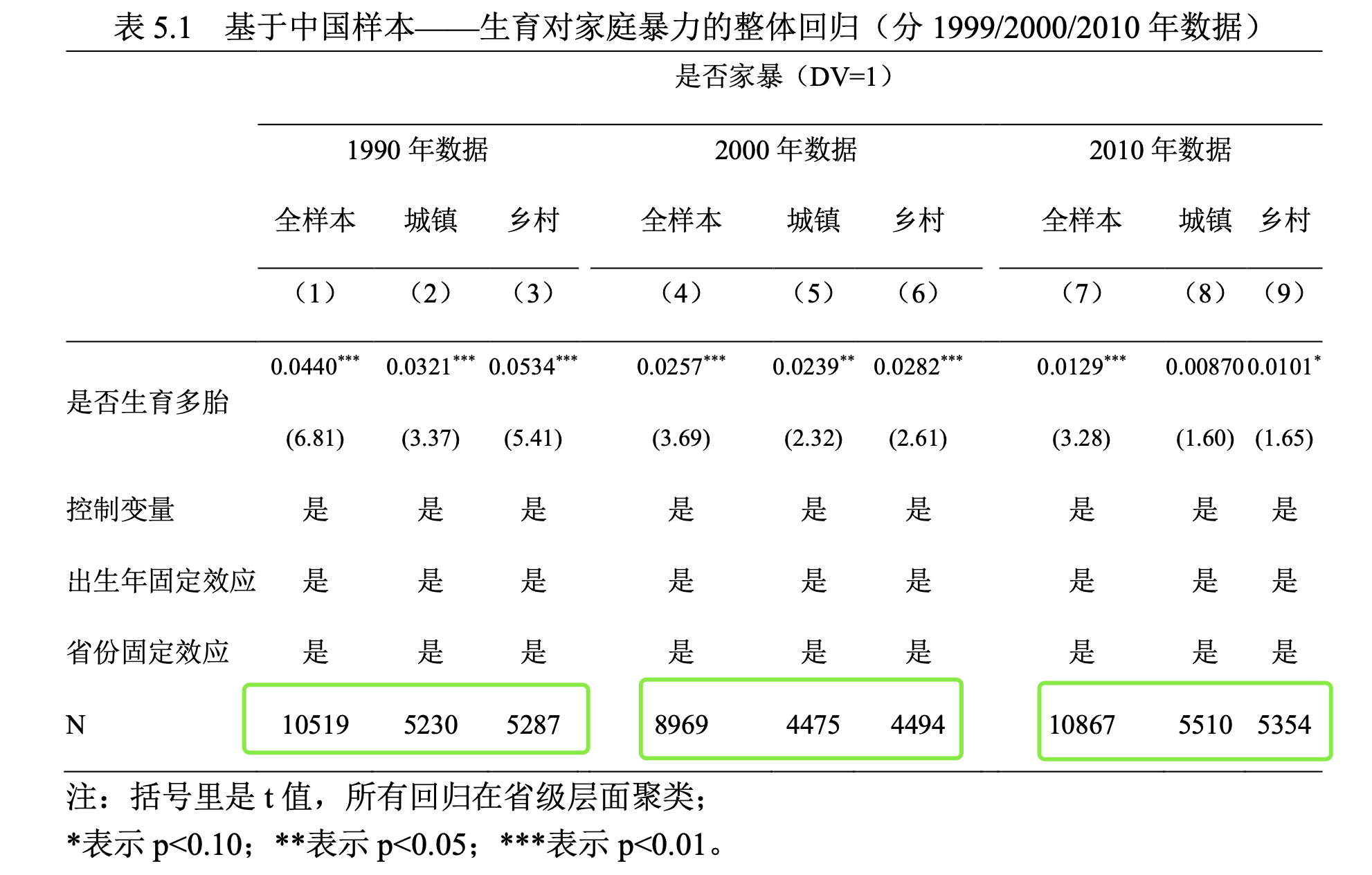
10519=5230+5287?
8969=4475+4494!
10867=5510+5354?
大概率是做逻辑回归的时候,子样本有些组存在因变量一致的情况,回归结果自动删除了一些样本。
2、表5.1中数据汇报错误
5.34%汇报成5.4%(感觉AIGC没那么蠢,不应该识别错误)
5.4%-3.2%=2.1%???喵喵喵

3、变量定义操纵
5.1表中的核心自变量“是否生育多胎”应该理解为家庭是否有超过1个孩子,分为孩子数量大于1和孩子数量小于等于1。她的定义为:

莫名其名的定义,很大可能有p-hacking的嫌疑。表5.1的结果也显示,2010年的结果其实已经不显著了。无论是practical significance还是statistcal significance。按照这种趋势,说明2020年家暴的情况已经消失了,那她的研究还有撒狗p价值?
4、分样本回归有不小的问题。
针对第三点做一下补充。2010年,城市家庭因为独生子女政策的实施,应该没有多少大于2个孩子的家庭。如果用“孩子数量大于1和孩子数量小于等于1”这两类来定义她的核心自变量“是否生育多胎”,那么就会出现城市样本的值几乎95%以上都是0,那还怎么跑逻辑回归?标准误估计大得吓人,自然无法得到显著的结论。这应该是她故意修改核心自变量定义的根本原因。
5、AI行文风格特征:
AI在分析回归结果的时候,经常喜欢用一个单位这样的行文措辞。一会一个水平、一会一个单位,大概率是杨女士忘了调整。

6、关于杨女士到底是用的逻辑回归还是LPM的问题
因为因变量是0-1变量,我一开始就默认对方是用的逻辑回归。但是她汇报的是t值,不是z值,那么应该还是用的LPM,草率了。但是LPM丢样本的可能性却反而没有逻辑回归大(OLS和MLE估计方法的差异),费解。