
其他人说规范性的比较多,我这边主要说实证吧。
关于杨景媛女士硕士生毕设实证研究中存在的主要问题总结
1.绪论
首先,我需要开宗明义地说,杨女士这篇文章的实证,在任何一个学校的《经济学学术论文写作》课程里都可以当做完美的反面教材。
这是一份罕见的,把缩约型经济学实证中所有方法论选择、规范性以及经济意义解释方面可能出现的问题及雷区都踩遍了的奇葩论文,这篇论文能沟通过盲审及院内答辩,让我非常怀疑武汉大学经管学院的整体学术素养和学术风气。
2. 关于实证模型及方法论的错误总结及修改方案
2.1 基于被解释变量性质的模型选择问题
首先,我们看杨女士的实证设计:

基于杨女士公式4.1的设计,被解释变量DV表征了P省份的个体i“是否遭遇了家庭暴力”,而从表4.1和4.3对应的变量统计结果可以显然发现,DV是一个0-1变量,其适用的模型应当是probit模型或logit模型。但是,在全文的分析过程中,杨女士并未对自己实证模型的参数估计方法论进行有效的叙述,而这也使得我们仅能够从公式4.1的形态进行判断——按照相关的学术规范,采用probit或logit模型时,被解释变量应当以P(DV=1)的形式,其表征了“DV为1的概率”而非DV的单一取值。
综上,我们则可以初步判定杨女士在针对中国及印度样本的、以0-1哑变量为被解释变量分析中采用了线性模型的设计,换言之以简单的线性概率模型(LPM)方法进行参数估计。这一方法并非实质性的存在问题,但其事实上有两个缺陷。其一是无法解释估计结果超过0-1范围的问题,其二则是其拟合数据因问题一而不具备经济意义,因此原则上不应当对模型系数进行经济意义的赋予和解释。但在杨女士第五章的回归结果中,大量地以百分比的形式解释线性回归的系数,这是一个非常不严谨、不符合经济学学术研究规范的行为。
因此,建议采用logit模型,并使用OR值分析或均值侧的边际效应分析(logit模型具备解析解,这使得系数可以替换为OR值)对系数的经济意义进行拓展和解释。
2.2 “固定效应”之辩
我们基于模型的设计逻辑和表5-1的展示成果,分析杨女士模型设计中存在的另一个问题。
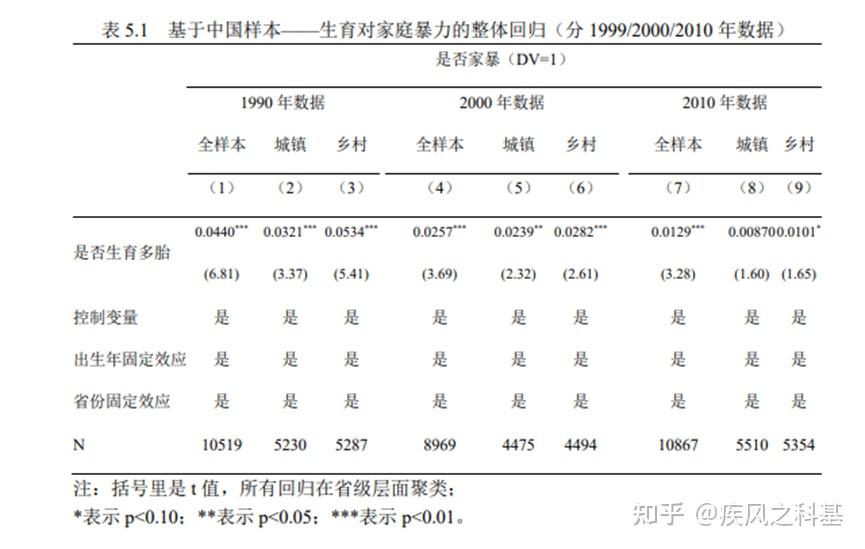
从杨女士4.1公式和表5.1的结果中,可以显然发现,杨女士采用的是“固定效应回归模型”。这显然是受到了前人面板回归思路的影响,试图使用高维固定效应(HDFE),换言之“最小二乘+个体哑变量”(LSDV)的控制变量思路,试图对模型估计中可能存在的有偏性进行处理。
是否可以这样用?可以
但她这样用是否正确?Not even wrong
需要说明的是,这是一个非常错误的操作,不仅是方法论本身的适性问题,同时也是由于一部分操作和方法论思路的缺失。
首先,杨女士的数据集是基于人口问卷数据,并通过多年份的问卷数据进行拟面板化整合。她的惯性思维认为,多年分数据进行了面板化整合后,就构成了一个“面板数据”,而陈强的书上说“面板数据,尤其是短面板数据使用固定效应基本优于随机效应”(笑,陈老师的这个话其实没太大问题,但有适用范围),所以一没有做豪斯曼检验二没有对“固定效应”的基本控制逻辑进行有效理解,就直接糊了个模型上去,这是一个非常大的规范性问题。
事实上,陈老师的“短面板”是基于“一个规整的面板数据”的逻辑进行思考的,而这种多年问卷,尤其只包含2-3个时期的问卷数据,并不是一个规整的面板——由于大量的人口样本流动迁移,增加或减少、家庭结构变动导致的年份之间无法有效对应的问题此起彼伏,这类数据集的多年份整合更接近医学或社会学领域构建的“反复测量数据”,而数据集里真正存在的问题,其实是多次测量以及各年份人口异质性的大量存在而导致的异方差问题。
在计量经济学的一般理解中,面板数据中存在的强烈异方差性被理解为一种“方差的随机游走”,因此事实上采用了针对异方差性的GLS或FWLS模型进行处理——大家也可以记住这一点,随机效应模型事实上就是计量经济教材上“针对异方差性进行的模型估计”,这也是stata中xtreg的re选项可以无需xtset直接运行的原因(扯远了)。
综上,正确的方法论应当是使用随机效应模型进行估计——当然省份、出生年份等要素确实是分组差异的重要来源,因此可以作为控制变量进行控制,但这种控制并不是一种合理的固定效应,而应当被理解为一种分组变量或控制变量,是以不能以“固定效应”的表述对自身的方法论进行描述,这里对方法论的介绍和后续的分析存在严重的规范性问题。
2.3 消失的内生性和稳健性
杨女士第五章实证里缺失了两个重要的问题,就是她的文章里不存在对其研究关联的内生性和稳健性分析。在其研究的生育对对家暴行为的影响关联当中,存在两个内生性的来源:
(1)生育与家暴之间的双向相关性。事实上这个问题在杨女士自己所展示的印度问卷中就提到了,家庭暴力行为中存在婚内强奸和强制生育等行为,这意味着家庭暴力存在对女性生育行为的反向影响。因此,在后续的实证过程中,应当排除这种要素对模型结果造成的影响,采用合适的工具变量对这一问题进行处理。但杨女士的文章中显然没有内生性检验和工具变量分析的过程。
(2)由于女性社会地位或社会价值而导致的自选择问题。这个问题在杨女士自己的描述性统计中也明确的地表达了——存在无工作、家庭主妇地位的女性,存在受教育水平和社会地位较低的女性,这些因素都会在模型中造成相对严重的样本自选择问题,因此需要引入heckman模型进行处理,杨女士的文章里也没有这个内容。
最后,实证模型中完全不存在稳健性检验,而第六章的事件分析模型中也没有安慰剂检验,两章模型中模型设计的抗扰动特征无法得到有效的证实,实证结果可靠性不足。
2.4 拟自然实验的基本设计问题简述
杨女士第六章使用了一个很“奇怪”的拟自然实验(她称之为拟事件研究法)思路分析生育对家暴的“动态影响”。

这里首先需要说明一个问题,就是基于拟自然实验的模型设计,包括事件研究法和DID这两大方法论,都不应当被理解为一种“动态分析”——事实上,这类方法所得出的参数估计结果都是静态的、被称为“处理效应”的系数,杨女士理解的“动态”是基于时期的定义,但这种定义并不应当被认为是“动态的”,这里并不涉及动态的时滞或继起问题,仅仅是一个事件造成的短期影响逻辑,因此仍然是一个静态分析。
当然,以我的学术逻辑和理解,我其实非常欣赏杨女士能够使用这么一个具有突破性的、“我没有见过的”研究方法(星星眼)。我最喜欢的其实就是这种“啊,原来还可以这么做”的实证文章,但杨女士这个突破性的设计作为文章最大的亮点,也是文章最大的糊点。
因为,杨女士似乎并不理解“匹配”是怎么个事儿。
在她方法论的叙述中,是基于“匹配方法”在30000多个样本中创造了一个“280样本”的小数据集(笑)。这个匹配方法非常抽象,因为她的叙述是“年龄相同”以及“人口特征Xj=Xi相同”,换言之我可以理解为她的匹配方式是基于实验组和对照组人口特征完全相同的简单匹配方法,这也是她流失了99%样本的基本逻辑(笑)。
应该说,这个匹配的思路,是灾难性的——其实杨女士的方法属于一个很经典的“多期DID”,而且是比一般的多期DID要复杂的——因为她的数据预处理过程中涉及上述的逐年匹配问题,如何将特征明确的实验组和庞大的对照组进行有效匹配,其实在当前针对多期DID的研究中也是一个难以解决的问题。所以对于这个问题,我的理解是,只要能做出有效的匹配并构建合理的样本,同时做出实验组和对照组在事前的统计比较,那么匹配就是正确的。
综上,三个问题。(1)匹配后实验组和对照组的事前描述性统计结果不存在;(2)匹配后的样本严重不足,甚至实验组“到底有多少个人”都没说明白;(3)匹配的方法论过于简单,缺乏一般逻辑。
这里我也提供一个思路:其实杨女士的实验设计有可取之处,她事实上是基于生育年份进行的匹配,那么完全可以将生育女性按生育年份分组,并通过PSM方法,选择在当年具备适龄特征(25-35岁)的女性进行逐年匹配,最好做到1:3-1:4的匹配率,从而获得对照组的样本。这样简化了方法论,不用大浪淘沙的瞎搞,而且实验组和对照组在人口属性上也具备相似性,样本规模也可以保证在3000(估计)左右,这一章的经济意义至少得到了保证。
3. 实证数据收集及预处理中存在的主要问题
3.1 灾难性的描述性统计
这么说吧。杨女士在第四章的两个描述性统计(表4.1和表4.2)是我学术生涯中看过最烂的描述性统计表格。
首先,表4.1的描述性统计暴露的主要问题是,杨女士应该没有进行数据的预处理。一般来说,在经济学的模型中,需要考虑实证数据前后的一致性,换言之描述性统计中的样本数据集中如果有100个样本,那么后续模型中如果不是存在特殊的问题(如异质性分析、稳健性检验抽取一部分样本,或者固定效应模型由于组内共线性导致样本缺失,tobit模型吃掉了一部分无效样本之类的情况),模型中的有效样本也必须是100个。而我们看看杨女士的表4.1:
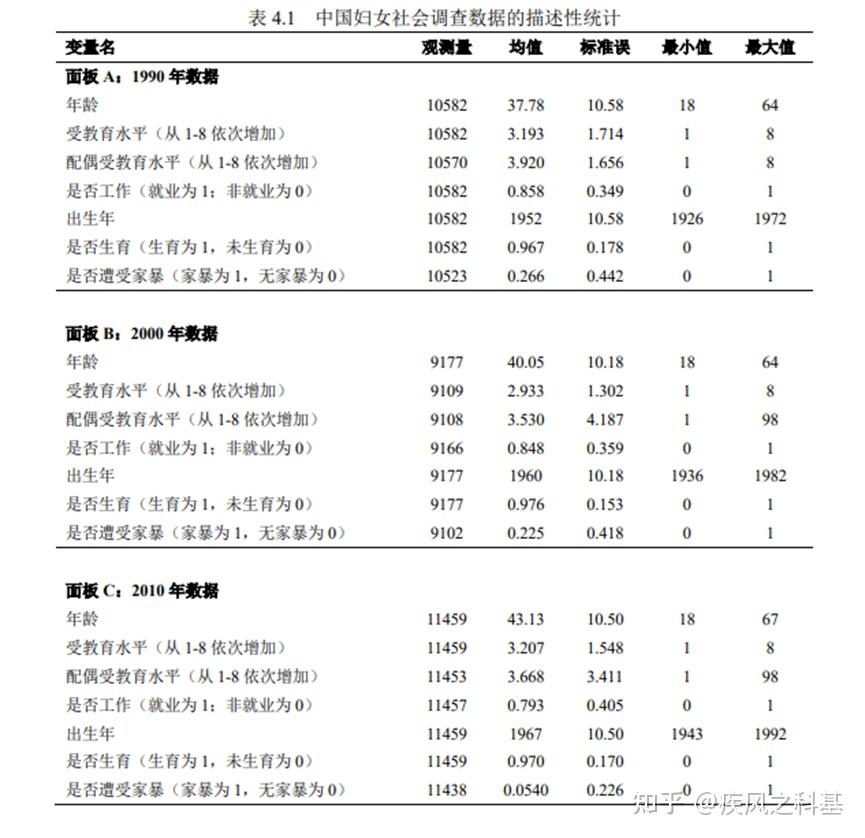
以她样本描述性统计中的参差程度,根据我的经验,我估计她后续模型中大概有1%左右的样本是存在缺失的。
此外,还有两个问题,比如“六旬老妪离奇产子后被丈夫深夜殴打”、“受教育水平高达98的超人类男性”。这里的问题在于,其一杨女士没有合理剔除模型中不在适婚适育年龄的样本,这里应该保留样本到25-45岁以提高样本代表性。而另一个错误就很离谱了——通常问卷设计中98、99这些代码是错误码,指向“不知道”、“不适用”或“拒绝回答”的无效样本,如果结合前面“数据筛查”的叙述,杨女士显然是没有完全剔除无配偶、丧偶或离婚的样本。
综上,中国数据部分,杨女士应该是直接拿来问卷就搓数据了,根本没有做预处理和数据清洗。
而表4.2更是离谱,因为大概有90%以上的样本在后续的模型中必然是“无效的”。请看:
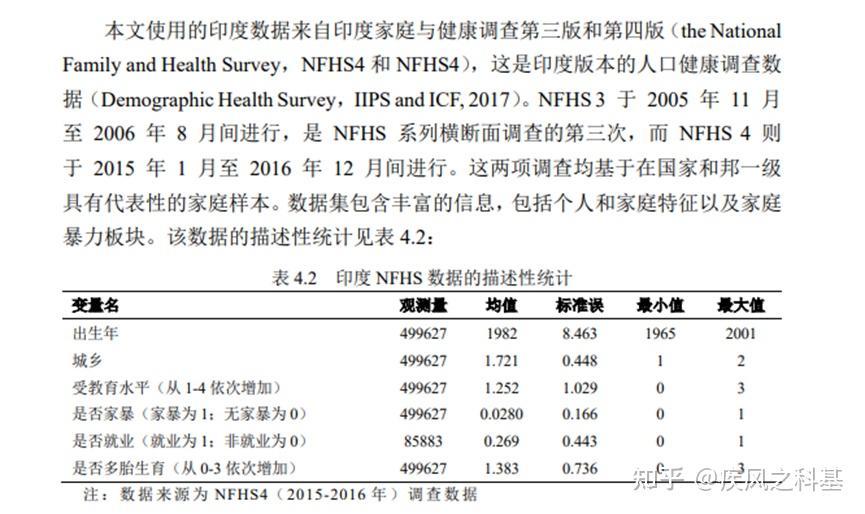
全样本规模是49万,但是否就业这个问题的对应样本是85883.也就是说,如果就业是后续的模型控制变量,那么杨女士这里使用的样本中大概有80%以上是应当被清洗的。
事实上,这里也是有办法补救的——这部分女性到底是因为什么原因而不具备工作的?从杨女士的样本中,一个很大的问题在于她收集的女性样本出生年最大值是2001,推测对应样本年龄可能在4-15岁,换言之不具备合法的工作身份的样本可以进行剔除。进一步地,“家庭妇女是否被认为是无工作的”这个问题事实上是大量妇女不回答相关问题的核心原因,可以把这部分样本定义为work=0
此外,一个非常离奇的问题是,NFHS问卷中受教育水平的最大值是4,但杨女士的描述性统计中仅有1-3的样本,也就是说“高等教育女性在样本里是不存在的”。换言之,杨女士的样本存在显然的样本选择或自选择偏误,不可以作为代表性的样本。
然后,4.3又给我一发重击
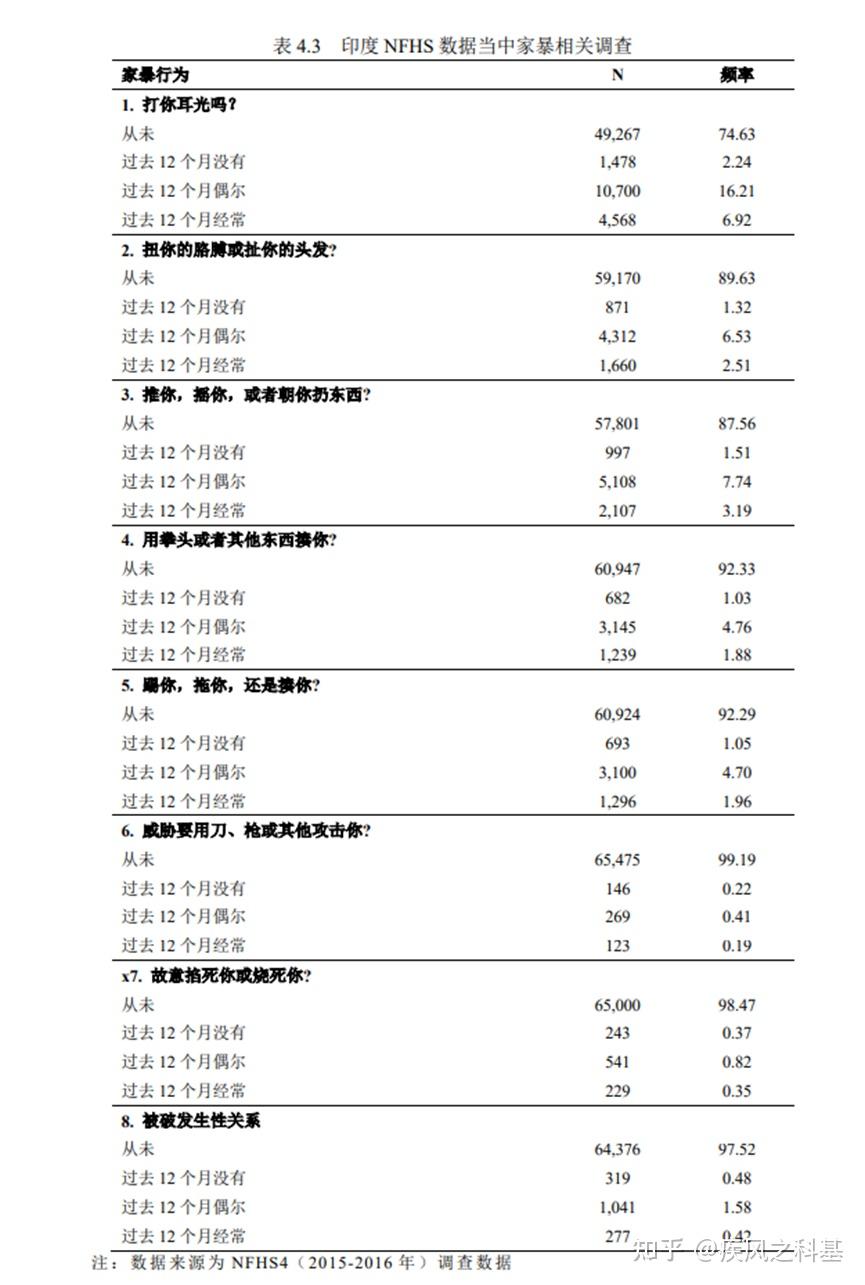
从相关描述看,受到家暴问询的女性事实上在他的有效样本里占比可能也就10%左右,而杨女士非常不负责任地将49万样本全部进行了展示,换言之她根本没有做数据预处理,只是随手把描述性统计放出来了。
所以,杨女士到底做了什么?她的数据预处理,总之在我这是彻底过不了的,这数据属于是放进重生池都能给重生池炸了的,简直臭不可闻。
3.2 280个样本?
在杨女士第六章的描述中,中国样本仅有280个进入到了模型设计中,而印度样本也大概率受到这种影响,换言之99.9%左右的样本被吃掉了,模型设计显然不存在代表性,第六章整章的模型结果都是缺乏解释效果的。
在这种情况下,由于样本统计特征的剧烈变化,杨女士应当在第六章对自身使用的样本重新进行描述性统计,但她没有做,这一点在学术论文里是致命的,但看在她的文章已经收到多次致命伤的前提下,这个问题好像已经是个小问题了。。。
4. 模型结果的问题
4.1 联合统计的重要性
杨女士的第5章,在模型结果方面也存在很大的两个问题。其一,是在她的模型结果中完全没有联合统计量和拟合优度R方的展示。虽然这俩玩意已经被现在的学术研究喷烂了(笑),其对于模型的实际价值确实不如核心系数的解释效应,但联合统计量和拟合优度仍然是标定了模型实际有效性的参考指标,尤其对于一篇需要高度规范性的硕士毕业设计而言,这样的内容不应当省略。况且杨女士在其文章之内没有对控制变量的内容和系数进行任何表述,这又是一个严重的规范性问题(一般而言,基准回归部分应当对控制变量的回归效果进行基本的展示,以证实控制变量的实际使用和回归效果,从而验证控制变量的选取有效性。)
其二,是她比描述性统计还要混乱的样本规模。从5.1看,不出所料,每个模型缺失规模基本在1%-5%左右;而表5.3就更离谱了:
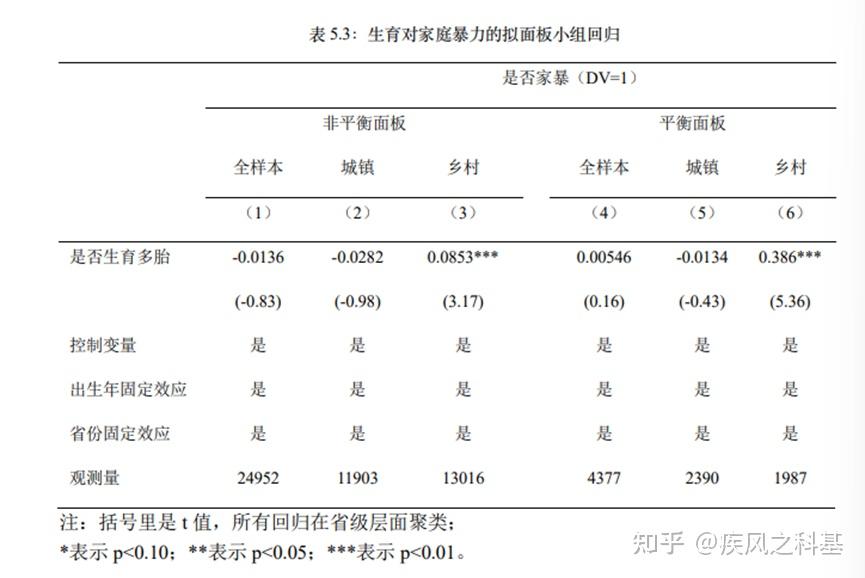
按照5.1,三个年份的有效总样本规模分别为10519、8969和10867个,对应30335个总样本,而5.3又被吃掉了20%的样本,后面更是拥了一个完全不知道思想感情,硬干掉了80%样本的所谓“平衡面板”。
然后是印度样本,表5.4突出一个“我可能没有清洗数据,但我没有清洗数据不太可能”:
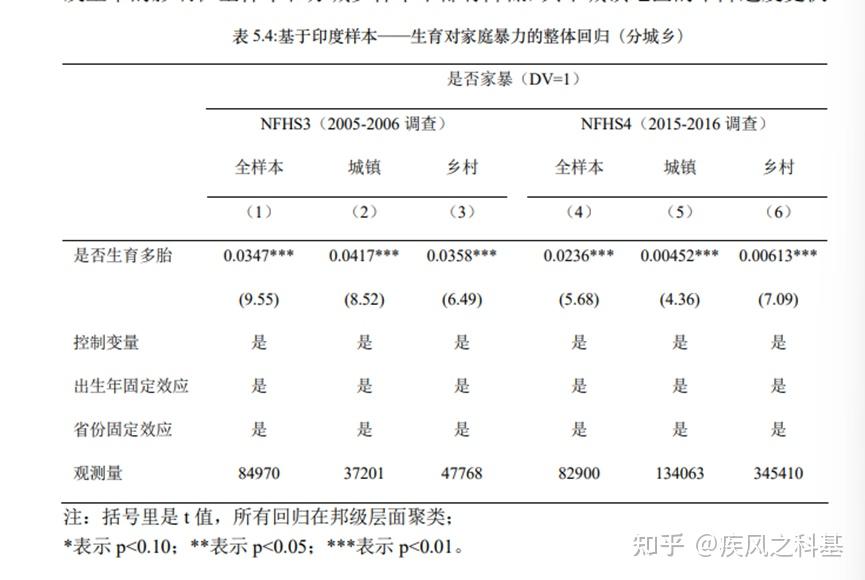
我就想问,NFHS4的总样本数到底是80000样本还是400000样本?
注意!上述问题下我还没有讨论系数显著性的更抽象的问题!按照表5.3的结果,她的假设根本不成立!
4.2 第六章的灾难性实证结果
第六章的结果是灾难性的。这里的问题主要体现在杨女士和她的导师郭先生缺乏最基本的学术论文写作“扬长避短”和“讲故事”的素质。
首先,我说下事件分析法或者DID成立的基本前提假设。这种拟自然实验的一个根本逻辑,是要验证“时间点0的处理行为产生了实际的经济或社会效果”,也就是说,事件分析法需要得出两个结论:(1)我的处理行为导致了结果;(2)这个效果必须是由我的处理行为导致的,而不能是由于事前就存在的实验组与对照组的显著差异。前者即“处理效应”,而后者则是“平行趋势假设”。(1)和(2)的存在构成了DID模型能够处理内生性问题的基础(当然家暴行为本身的内生性也没被考虑进来,麻了。)
那么我们看看杨女士的模型结果:
首先,6.1没毛病,这是一个很漂亮的显著结果。
其次,6.2有问题,前后都不显著,也就是说异质性分析对样本的进一步侵蚀导致触发了模型稳健性问题,结果不显著——而这又意味着图6.1中的模型存在稳健性问题(笑)。
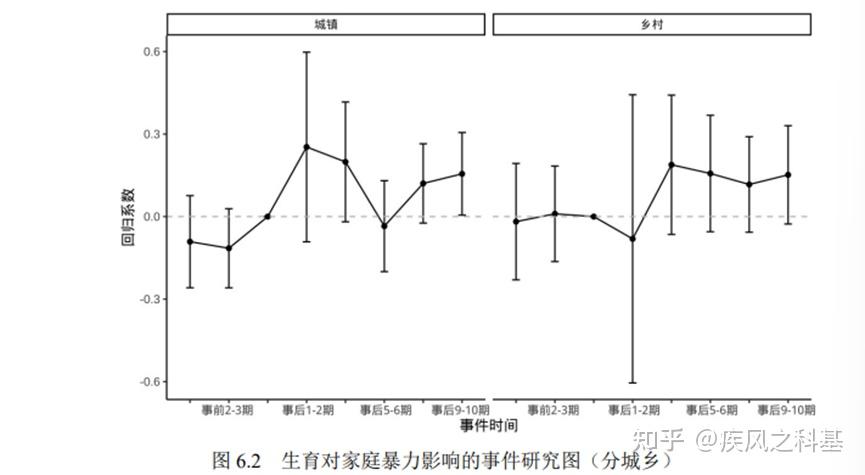
图6.3-6.6的异质性分析也存在这种问题,可以观测到6.3右图、6.4右图和6.5右图的显著性非常差。至于杨女士将这种分析称为“调节效应”,我只能说,你开心就好。
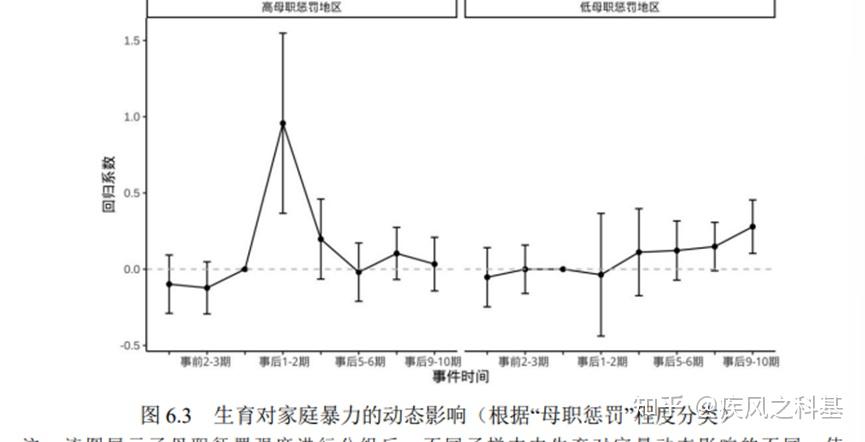
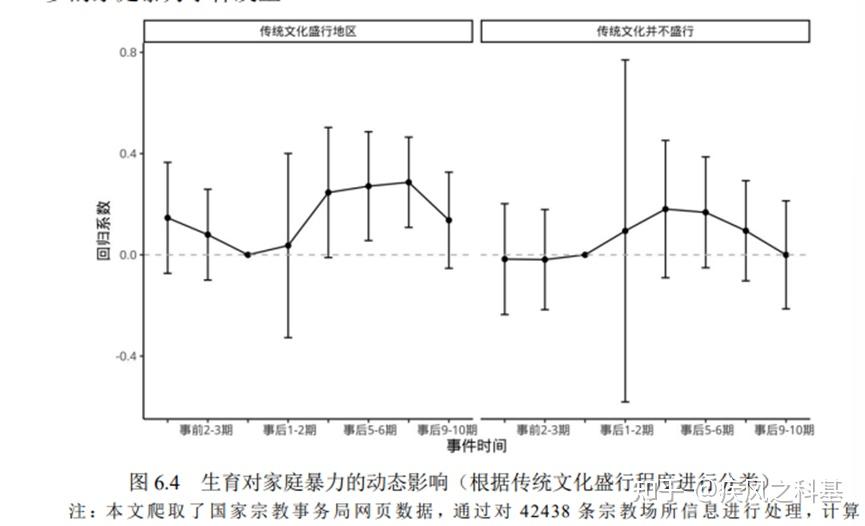
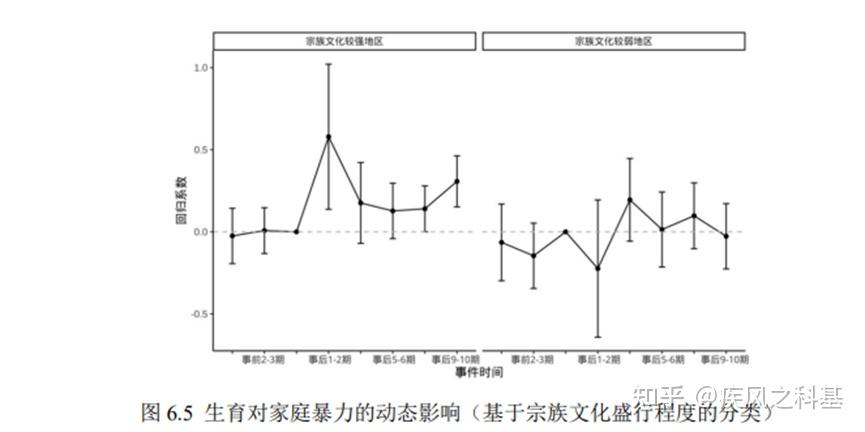
如果是我,我打死也不做这几个异质性分析。我的解决方案是,把把被解释变量进一步拆分。因为无论是在中国还是印度的问卷当中,针对家暴的提问问题都是有多个的,我完全可以以评分的形式替代0-1变量得出进一步的合理结论,没必要对着一个数据在这里死磕。杨女士的论文在数据的选择和实证模型的设计方面存在非常严重的灵活性不足问题,这是他实证最终无法解释理论的一个根本性的问题,是一种基本的学术思维和学术素养的幼稚性的体现。
而印度模型最大的问题在于,这个模型的结果不符合平行趋势假设。仅从图6.7就可以观测到,家庭暴力所受到的影响在事前就存在显著的实验组与对照组的组间差异,而这也意味着家暴行为受到的抑制,事实上在事前就已经发生了,而不是由事后情况导致的。因此,无法验证家庭暴力受到抑制的实质结果是由于生育而产生的,可能是由于是事前的一些原因而导致的。
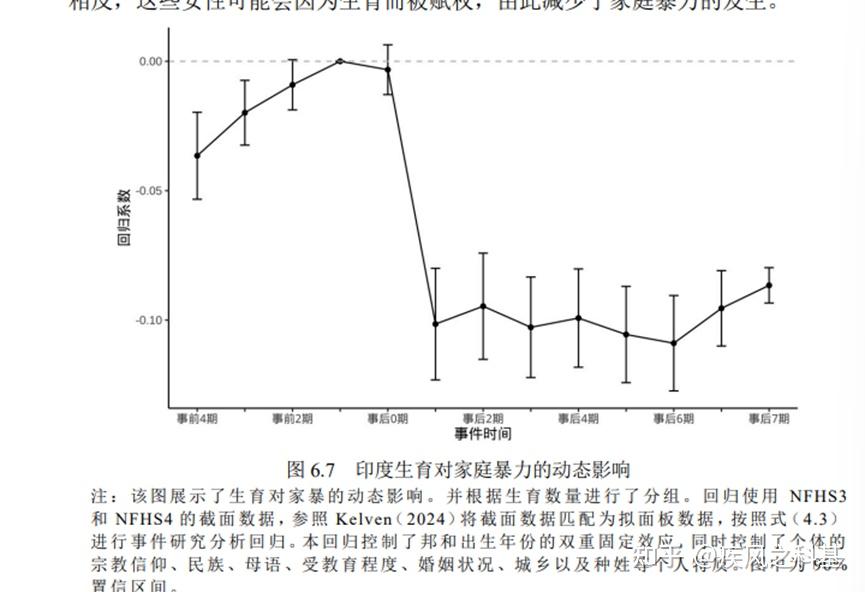
综上,杨女士第六章的实证论述过程,全军覆没,假设无法验证,这章应该删除。
5. 结论,以及关于知网的硕论吐槽
我记得在我们上学的时候,给我们教论文写作的老师就说过,“你们以后写毕业设计,一定不要去引用和参考知网上的毕设论文,博士的也不要看,参考格式和一些写作内容就可以了,因为能上知网的毕业设计质量是非常差的。”
现在看来,老师诚不我欺。杨女士的这篇论文,无论是数据的采选和预处理,还是模型的选择与设计,以及模型结果的展示,无不表现出一个不合格的硕士研究生在学术能力上的不足和学术态度上的不端正。这样的文章能通过一所985院校强势学院的学术委员会审议,是一件非常令人遗憾的事。
