
唔……一个很简单的问题,如果按照这种说法,那前几天的韩国coser事件就是一个典型的回旋镖——一个韩国coser,靠着正当职业吃饭,却被人造黄谣,那么造黄谣的人很显然应该被大力批判,被认为是塔利班吧。
那能一样吗?
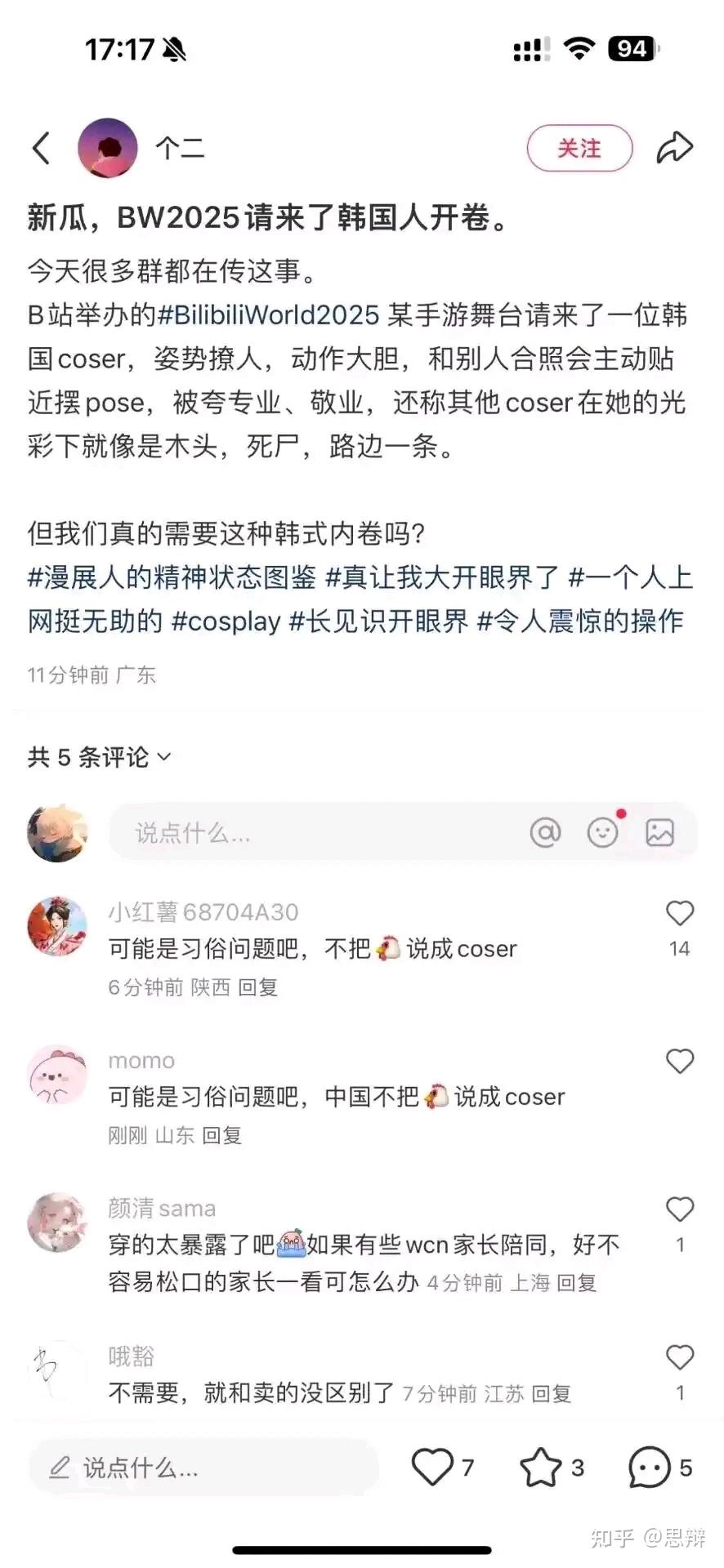
然后回到这个问题,很明显,实际上还是低估了某些人想赢的决心,为了贬低男性,她们是真的可以吹捧伊朗的。
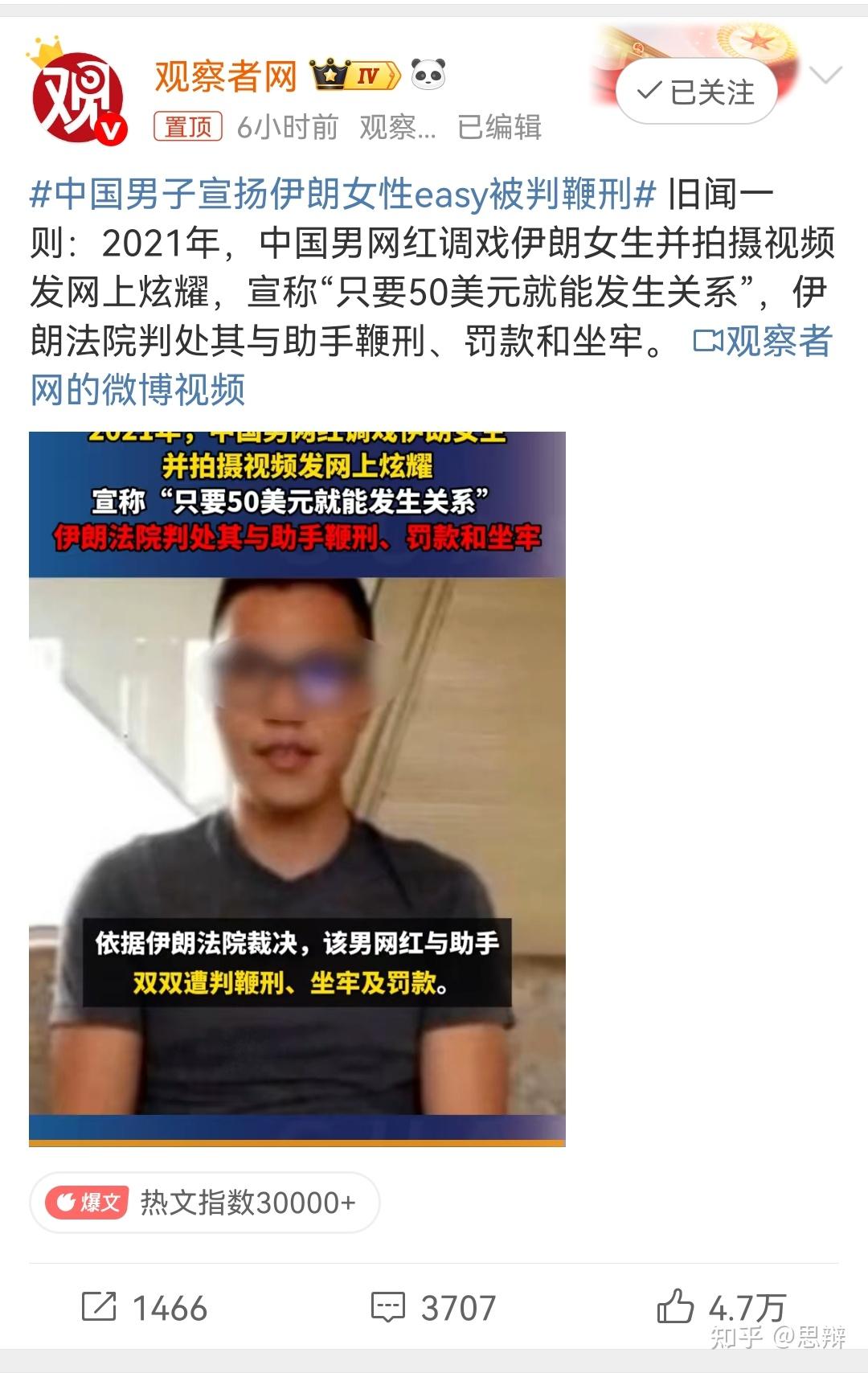
除此之外,为了给李欣莳进行支援,假新闻矩阵也开始出动进行烟雾弹释放:

如图所示,微博的大拇指为外赞,微博的爱心为内赞。很明显的是,从各项参数上看,很明显,伪造总赞数量最容易。因为外赞每条微博只能点一个,内赞可以点十几个,但正常人一般只会点3~5条评论的赞。无论是伪造有影响力的用户,还是伪造评论数量,难度均高于伪造总赞数。举个例子,伪造1000条评论需要1000个账号,但伪造1000个总赞可能只需要100,甚至更少的账号数量。
所以,在此基础上,能初步得出“内外赞理论”:
一般情况下,正常微博的内外赞比例是在5以内,一旦超过5,这条微博就有社交机器人刷赞刷流量(包含主动和被动两种形式)。一旦超过20,即属于大水漫灌的情况。此时也是假新闻最喜欢的情况。甚至可以粗略认定,内外赞比例超过20的情况,不是已经属于假新闻,就是正在制造假新闻。
这条微博的内外赞比例接近20,那么实际上这个辟谣的真实性,就不如“温柔的思辩姐姐是樱小路露娜”。
那么进行这些动作的目的是什么呢?答案很简单,结合今天这个问题,她们的目的是“推动‘对自己有利的共识’”。
那么上文这些新闻,对于推动共识的目的是什么呢?
首先,我们可以看看共识聚类的定义。什么是共识聚类?
共识聚类是数据分析中用于解决此问题的一种众所周知的技术。通常,目标是搜索所谓的中值(或共识)分区,即平均而言与所有输入分区最相似的分区。相似性可以通过多种方式衡量,例如使用归一化相互信息(NMI) 。
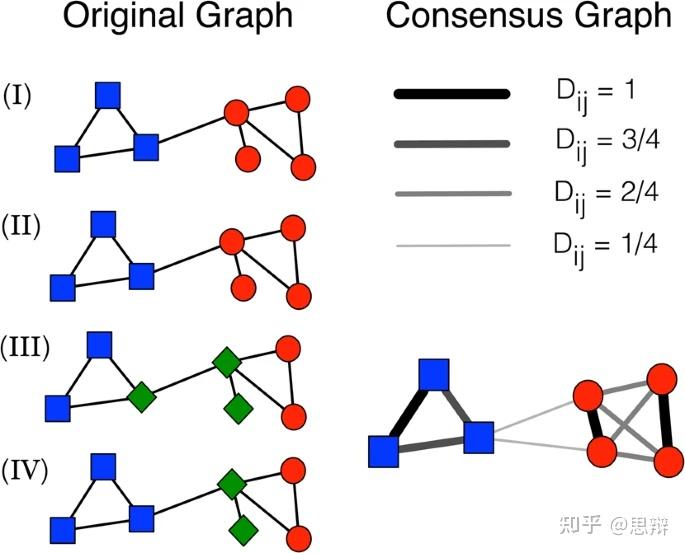
唔姆,如图所示,以上是共识聚类的示意图,图中可见两个聚类,其顶点分别由 (I) 和 (II) 图上的方块和圆圈表示。分区 (I)、(II)、(III) 和 (IV) 的组合生成右图所示的(加权)共识图。每条边的粗细与其权重成正比。在共识图中,原始网络的聚类结构更加清晰可见:两个社群变成了小团体,边“粗”,而它们之间的联系却相当薄弱。[1]
那么关于社交网络结构和共识之间的关系,我们可以看看Politics, Philosophy & Economics在2011年10月的这篇文章。
首先,我们如何模拟共识形成的过程呢?一种最易于理解的形式是,每个人也会在一定程度上受到他人的影响,同样用某个非负数表示。然后,个体会将自己的信念与所有对其有影响力的人的信念进行平均,从而更新自己的信念。所有个体同时进行此操作,从而得出新的信念。这个过程不断重复,直到最终社会影响力达到平衡——没有人再改变自己的信念。
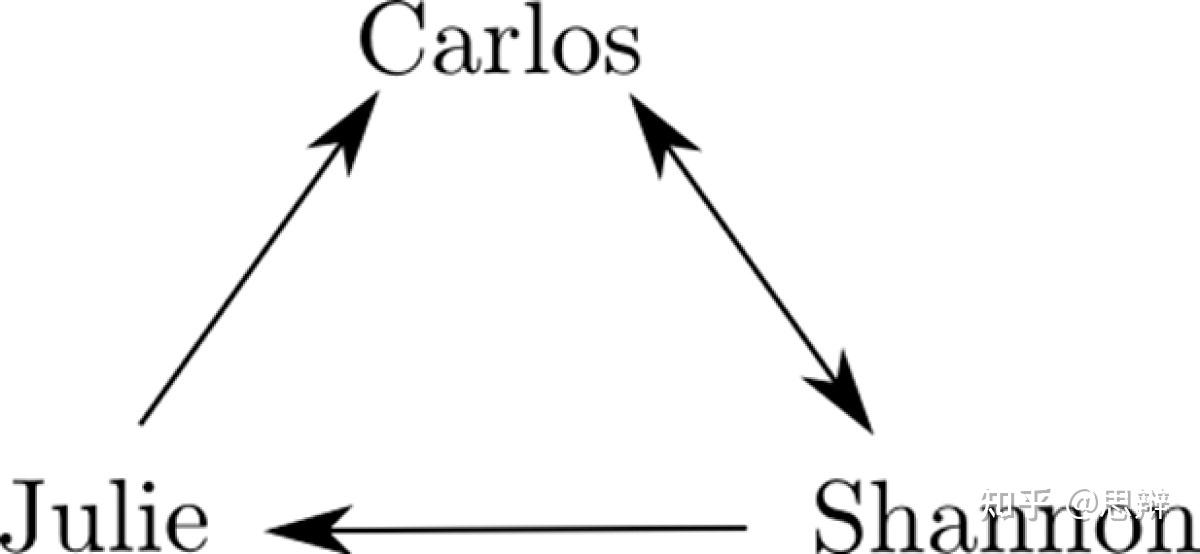
唔姆,如图所示,以上是一个收敛到单一共识意见的影响力图示例。沿着箭头方向,可以从任何个体到达任何其他个体。最终,该群体将达成共识。最终共识取决于每个个体受其他个体影响的程度,但可以通过一个相对简单的数学程序计算出来。
但现实不可能如同最基础的模型一样简单。
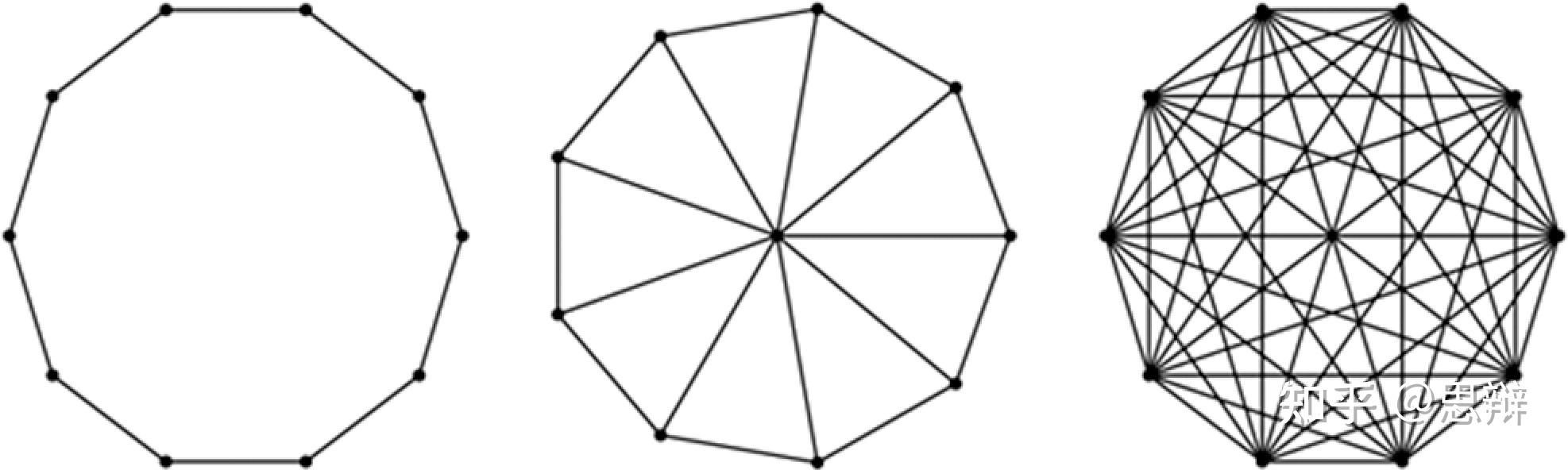
唔姆,如图所示,以上是三个图:圈图、轮图和完全图的示意图。首先,先限制社会影响的概念。不会允许任意程度的影响,而是会施加一些约束。假设每个人都有一群朋友(我们假设友谊是对称的,也就是说,如果我是你的朋友,那么你就是我的朋友)。同时假设每个人都受到她所有朋友同等程度的影响。
左侧图是循环,其中每个人恰好有两个朋友。右侧图是完全图,其中每个人都有其他所有人的朋友。也许令人惊讶的是,从最终的共识属性来判断,两者都同样好。这些与图2中间的图形成对比,在轮子中,一个人是所有人的朋友。在这里,处于中心地位的人对最终共识施加了不成比例的影响,因此过度扭曲了结果,使其倾向于自己的观点。
循环图和完全图之间有一个重要的区别。完全图达成共识的速度要快得多——一步到位。而循环图则相反,它几乎需要很长时间才能达成共识,尽管每一步都在接近目标。因此,如果人们不仅关心最终共识,还关注速度,那么他们可能更喜欢完全图。
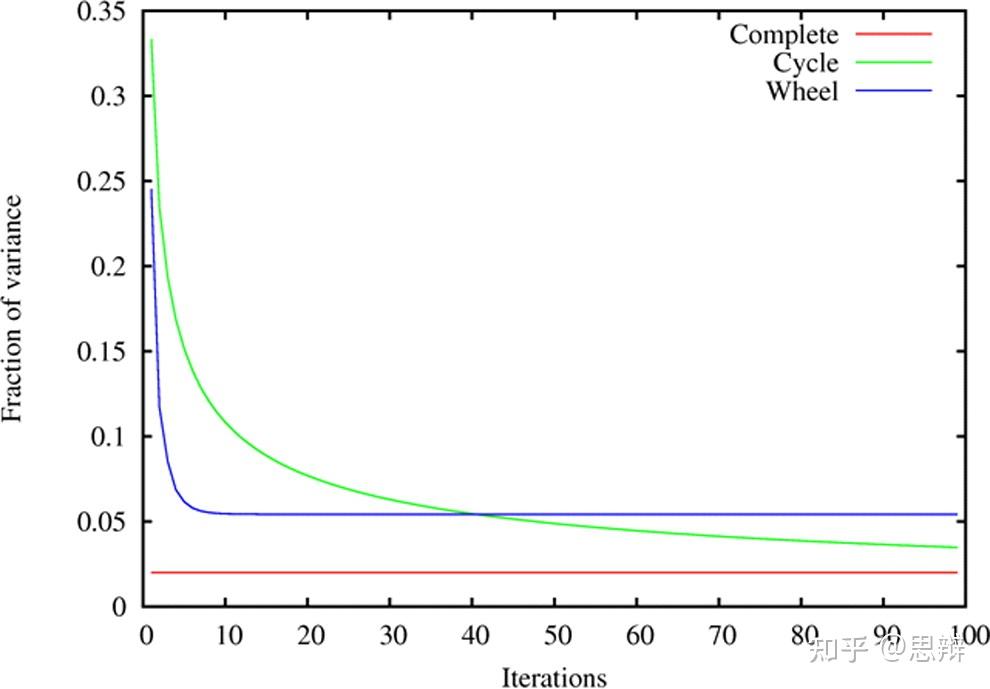
唔姆,如图所示,以上是使用线性池化的周期、轮子和完全图的短期行为。x轴表示平均过程的迭代次数,y轴表示最终判断与真实值的差距。
图结构也会影响该模型达成共识的程度。非连通图无法保证一定能达成共识。即使是连通图也可能存在持续的分歧。例如,假设一个由两个人组成的社区,他们各自认为与自身信念相差 0.5 以内的人是可信的,因此值得考虑。如果一个人的信念为 0.1,另一个人的信念为 0.9,那么这个群体永远不会达成共识。另一方面,如果一个人的信念为 0.4,另一个人的信念为 0.6,那么他们就会达成共识。
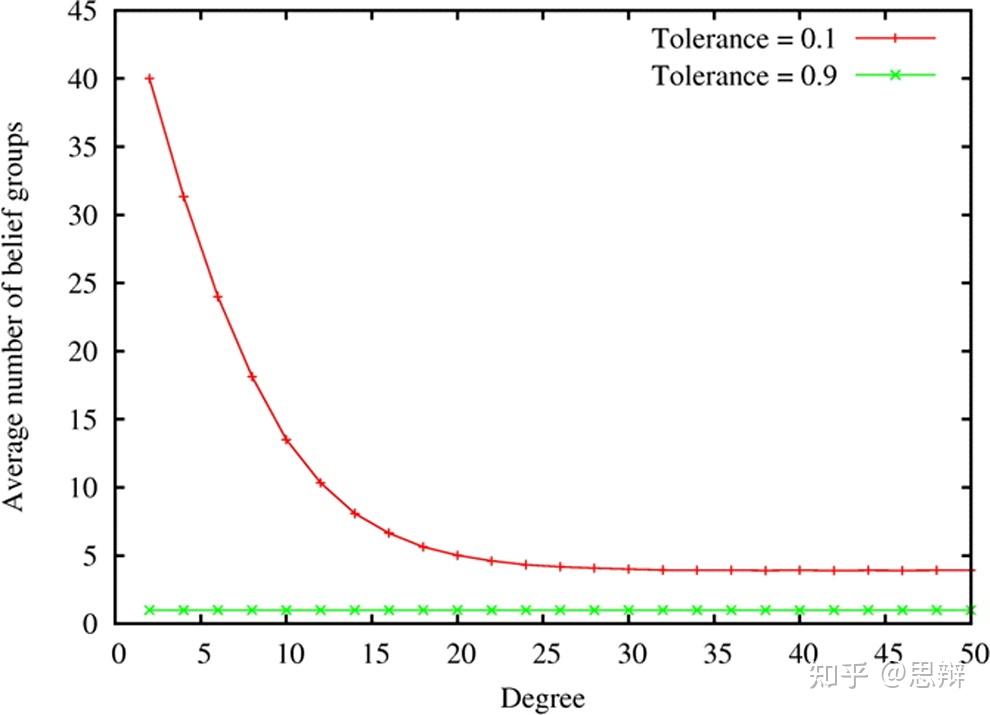
唔姆,如图所示,以上是不同x周期和两种极端容忍度下信念组的平均数量。如果不同意见组的数量为 1,则总能达成共识。数字越大,则表示达成共识的次数越少,或者根本无法达成共识。结论很明显,更高的容忍度(即拥有一群思想开放的个体)往往有助于在本文研究的所有图表中达成共识。
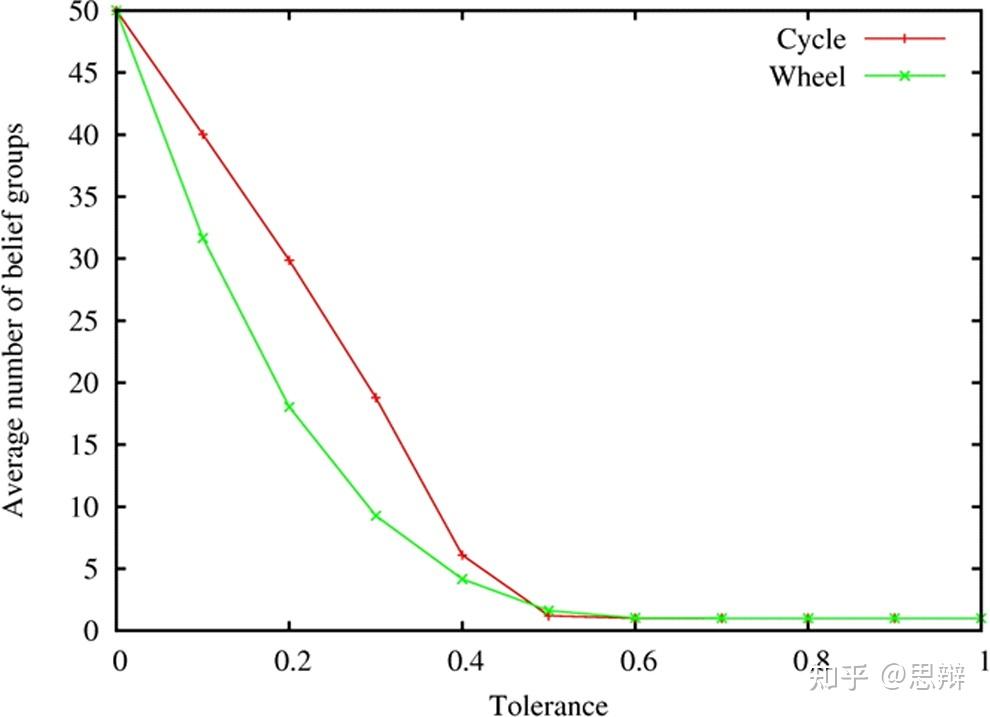
唔姆,如图所示,以上是周期和车轮信念群体的平均数量以及不同的容忍度水平。对于相对封闭的个体群体而言,即使这种连接是通过引入不规则性来实现的,增加连接数量也有助于达成共识。这很直观,因为一个人与越多的人互动,就越有可能与一个充当自己与他人之间桥梁的人互动。
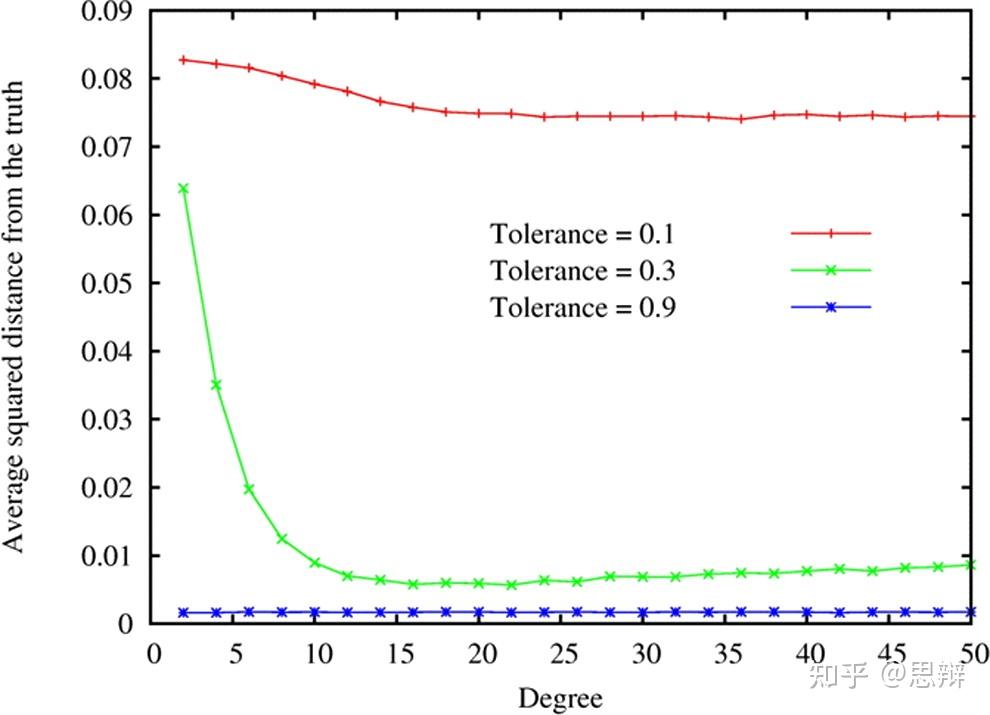
唔姆,如图所示,以上是不同周期和三个容差水平下与真实值的平均平方距离。这一结果的寓意是,某些类型的群体可能会从增加接触中受益,即那些由既不是极度开放也不是极度封闭的个体组成的群体。过于封闭的个体不太可能倾听他们遇到的新朋友,而过于开放的个体最终还是会通过其他来源获取信息。[2]
那么我们可以得出什么结论呢?
对于一个群体而言,如何快速实现共识塑造?我们可以总结出完全图、群体容忍程度高、连接数量多等规律。那么按照这个规律,我们是否能在这件事中进行归纳呢?
首先,通过这几天的媒体矩阵轰炸来看,支持李欣莳的社交网络很明显符合完全图的设定,而且由于新闻数量密集,发声的KOL众多,因此连接数量也多,那么除了女权以外,还有什么容忍度高的群体呢?
那么很明显,在这些条件都符合的情况下,最终形成了一个比较典型的完全图,而在里面夹带了大量假新闻的情况下,我们可以认为,“支持李欣莳的声音属于伪共识”,实际上可以大大方方地对李欣莳进行批判。
参考
- ^Lancichinetti, A., Fortunato, S. Consensus clustering in complex networks. Sci Rep 2, 336 (2012). https://doi.org/10.1038/srep00336
- ^Zollman, K. JS. (2011). Social network structure and the achievement of consensus. Politics, Philosophy & Economics, 11(1), 26-44. https://doi.org/10.1177/1470594X11416766 (Original work published 2012)